

早上瞄到這篇文章討論的 Tesla’s TTPoE at Hot Chips 2024: Replacing TCP for Low Latency Applications ,去年 Telsa 建了 Dojo SuperComputing ,今年就弄了一個新的 Protocol
TCP 已經是一個非常陳舊的 Protocol ,其中很多特性已經不再適合目前的網路環境,像QUIC架在UDP上層,增加安全性和速度。SCTP主打多連結,可靠性和安全,SCTP在電信環境用的比較多。基於 UDP 大量傳送資料的有 UDT (UDP-Based Data Transfer protocol) 等等
TTPoE 看起來應該是 Telsa 降本增效(名詞好用就拿來用)的實作,因為如果是使用RDMA之類的解決方案應該都有更快的 NIC Card 可以用(目前最快是 800Gbps 2 Ports QSPF-DD), 但是 TTPoE 是用 100G NIC 卡但是重新實做了整個 NIC Card ,雖然這樣講,未來仍然有升級的空間
我認為 TTPoE 的主要設計目地就是 Low Latency and Low Cost,因為 TTPoE 看起來是要做 HBM2HBM 的資料同步,Low latency 應該還是主要考量,因為他們要實作在 Hardware 上
而 data center(DC) 下是 data loseless 的環境,相對的網路環境比較好,如果有開啟 ethernet congession control ,理論下會丟掉的封包比較少,頻寬大。基於這個特性,TTPoE 就是做刪去法,將 TCP 協定中多餘的 Latency 去掉,仍然使用 IP 協定,保有和現有網路的相容性,以下這張圖就可以清楚的知道,TTP 是取代 TCP 的位置,上層仍然能夠跟 RDMA 接,其他 socket 或 APP 應該也可以,不過主要應該還是給RDMA這類高速記憶體協定用
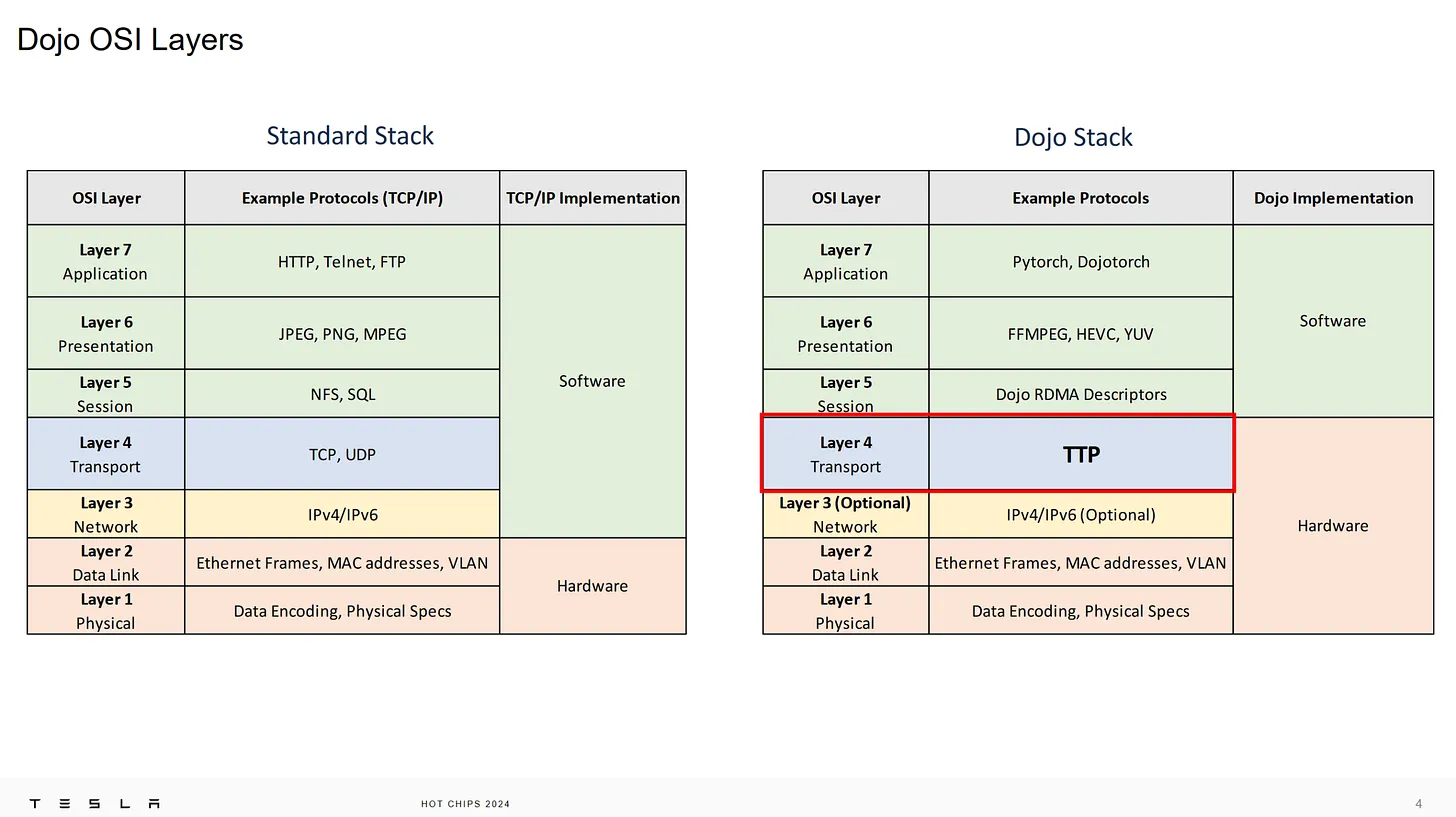
(註: 本圖來自 Tesla’s TTPoE at Hot Chips 2024: Replacing TCP for Low Latency Applications ,原圖應該是 Hot Chips 2024 Telsa 的 slide,以下不再重覆說明 )
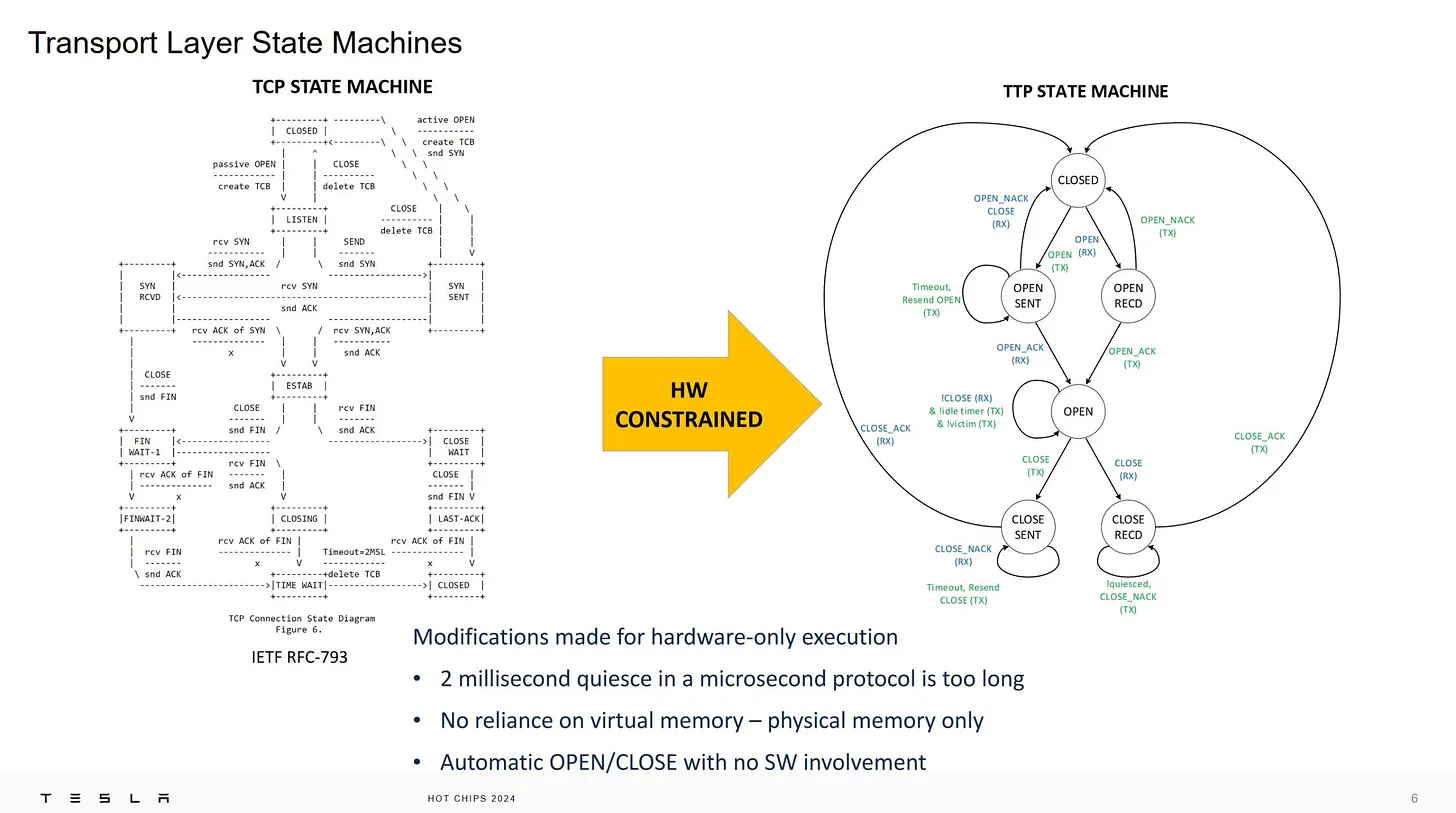
為了讓 Hardware 更容易設計,所以簡化了 TTP 的 Protocol State machine ,這是是目標也是結果,因為簡化 Protocol 也會簡化 state machine
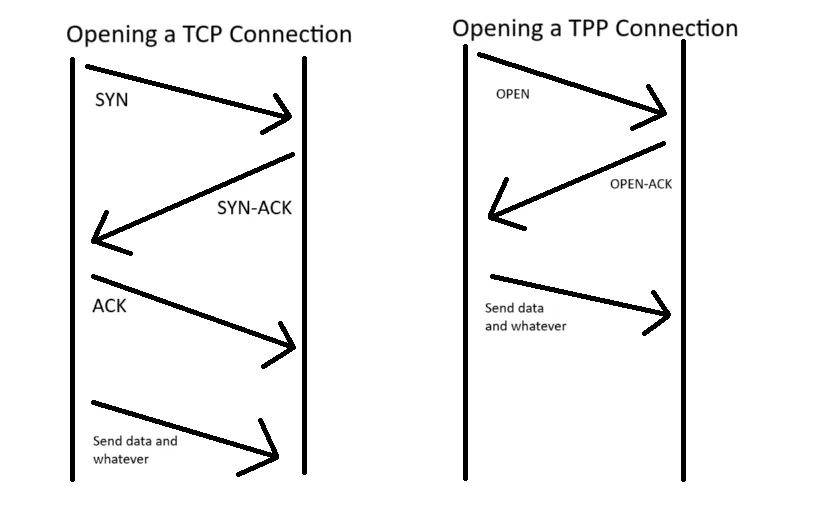
將 TCP 的 Three way handshake 改成 Two way handshake,其實 internet 防火牆需要這個機制判斷是不是真實連線,但是 DC 內部不需要,拿掉合理,也可以減少很多 Latency
有些人要加速會改 TCP ACK 到下一筆資料送出的時間,不過這會造成某些硬體加速器的問題
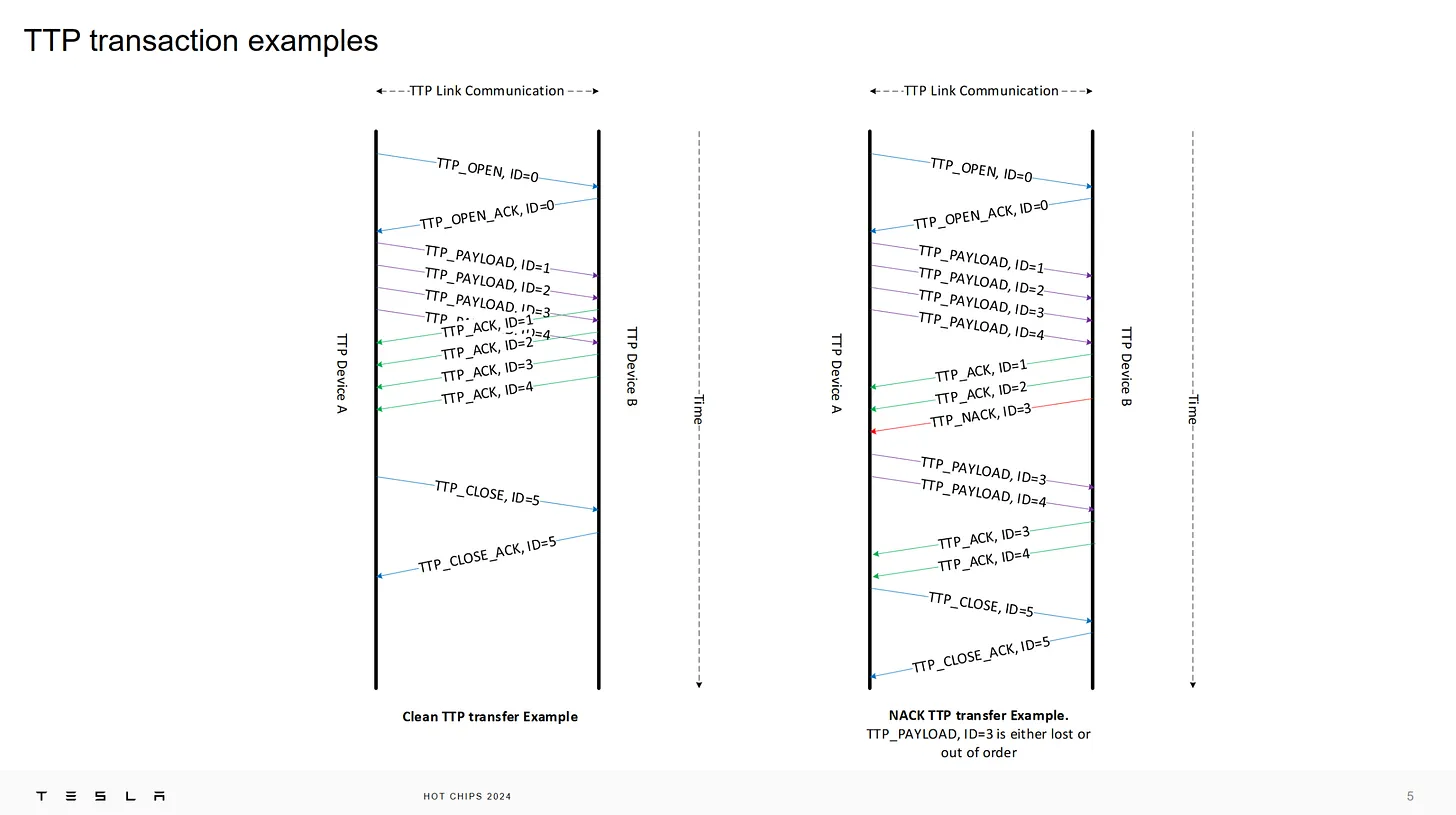
這邊應該是要將如果有個 Packet 是 NACK ,後面的 packet 都重送,這樣雖然會傳比較多資料,但是 DC package loseless 環境,這樣的機率小,可以接受這樣的設計
TTP 也拿掉 tcp congestion control 這個功能,如果只在 DC 用,這功能完全不需要,因為路上幾乎都是大頻寬,如果頻寬不夠就要從別的地方觀測調整,不是 Protocol 的問題,packet 的 sliding window 就設一個固定值,符合系統大部份時間都可以以最高速運作即可
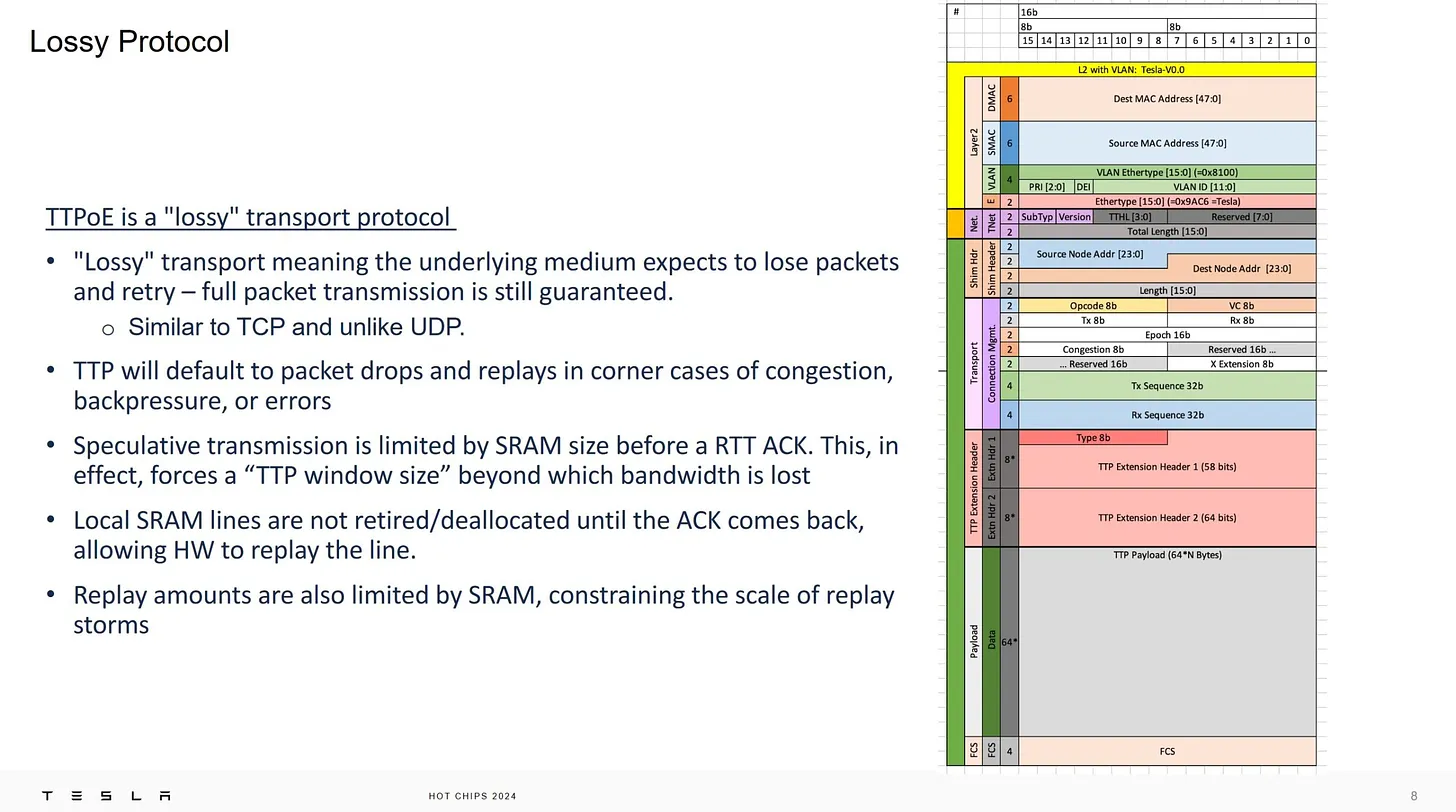
TTP Protocol 有些有趣的地方,Extension header 二個,第一個是指定 type 用的,第二個可能是未來用,這應該是固定大小,然後 Data payload 是 64 bytes 的倍數
有趣的是用 SRAM size 做 speculative transmission,這個設計我喜歡,好的演算法就是不需要演算法,讓系統自己去調整(self-adaptive),不過我懷疑這個就是 ethernet 的 tx buffer 講成高大上而已
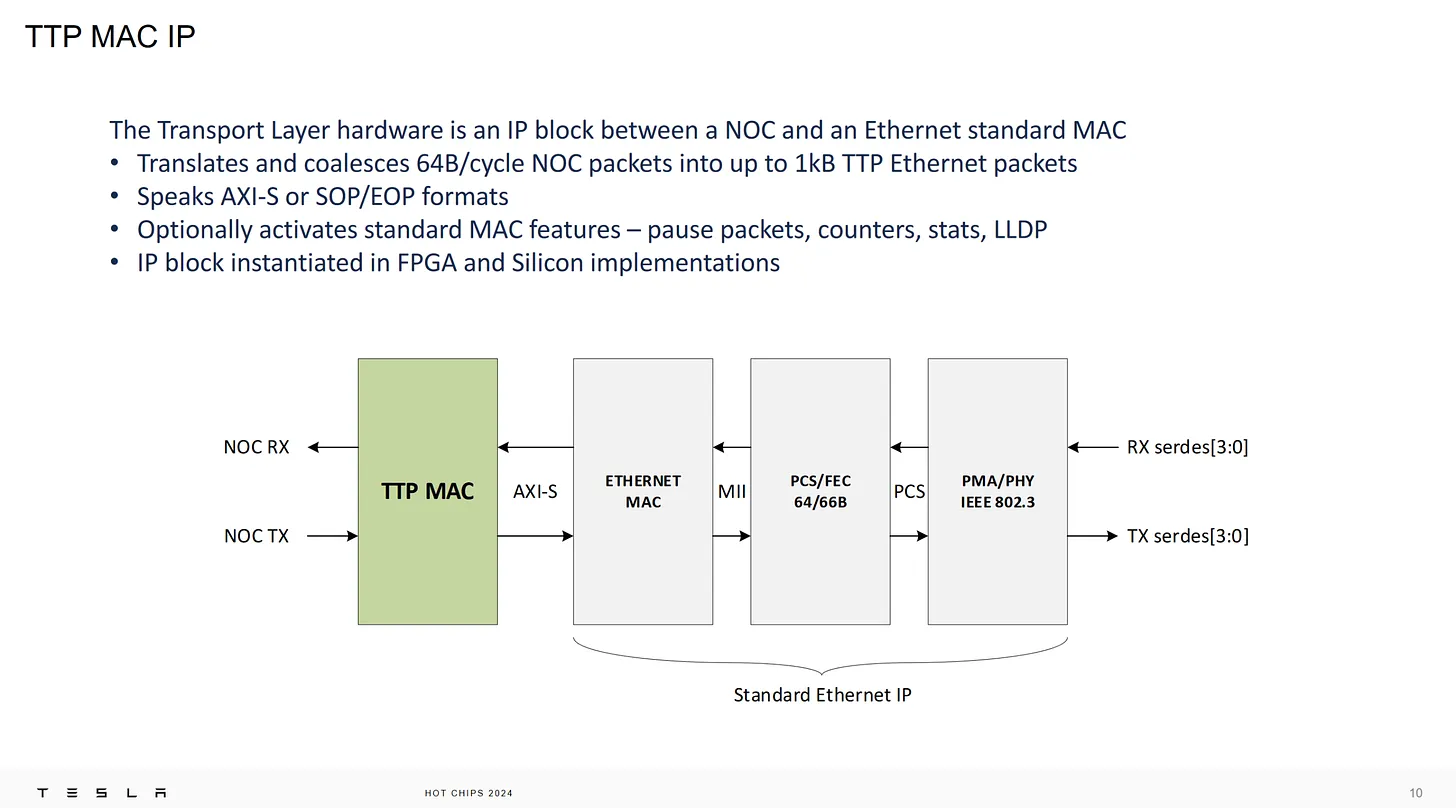
這意思就是前面還放傳統的 ethernet 架構,TTP mac controller 控制 ethernet 介面傳送資料,灰色部份都是現成的
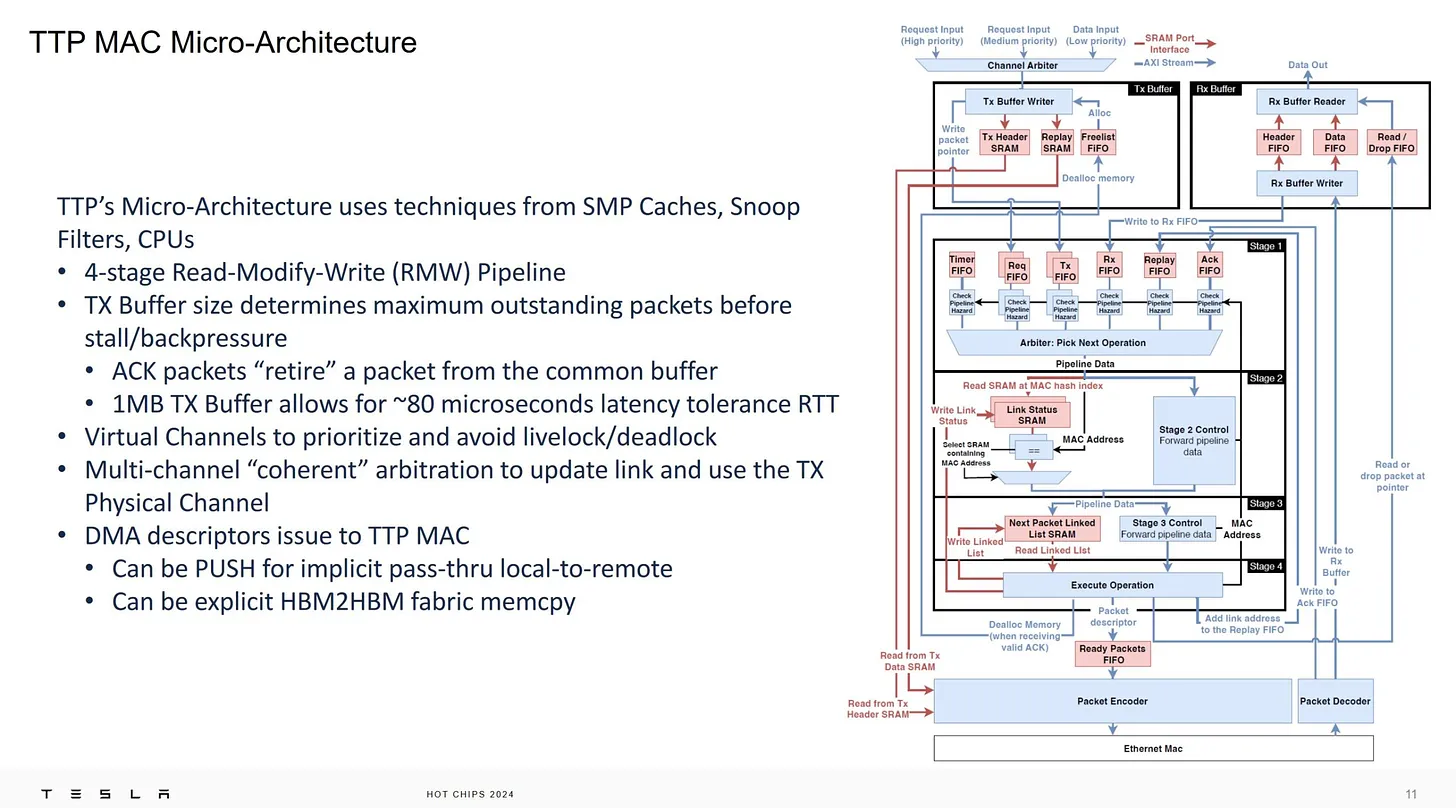
TTP hardware micro-architecture 設計
下方的 Next packet linked list SRAM,雖然講是 linked list SRAM,不過為什麼不做 array 當 ring buffer 呢?還是指的是同一件事,做過 NIC 卡就知道這種地方設計就固定是那樣,尤其是做成 hardware 又要結構更簡單,所以我才懷疑前面講的 SRAM 做 flow control 就是講這邊,如果 ring buffer 滿了就表示外面滿了
一般這種高階通常都有數個 TX/RX buffer ,不知道是不是因為專供 RDMA 用所以這邊就只畫上一個 TX/RX buffer ?而且不確定是不是因為一個 Buffer 頻寬就滿了(或是 FPGA 只能規劃 1MB,都有可能)
80 microseconds 在高速網路世界已經算很久了,算 OK
slide 最後一行我覺得才是真正的目地,如果是在 AI server 上要跑這個,那不用更高階的卡跑 RDMA 就很合理了
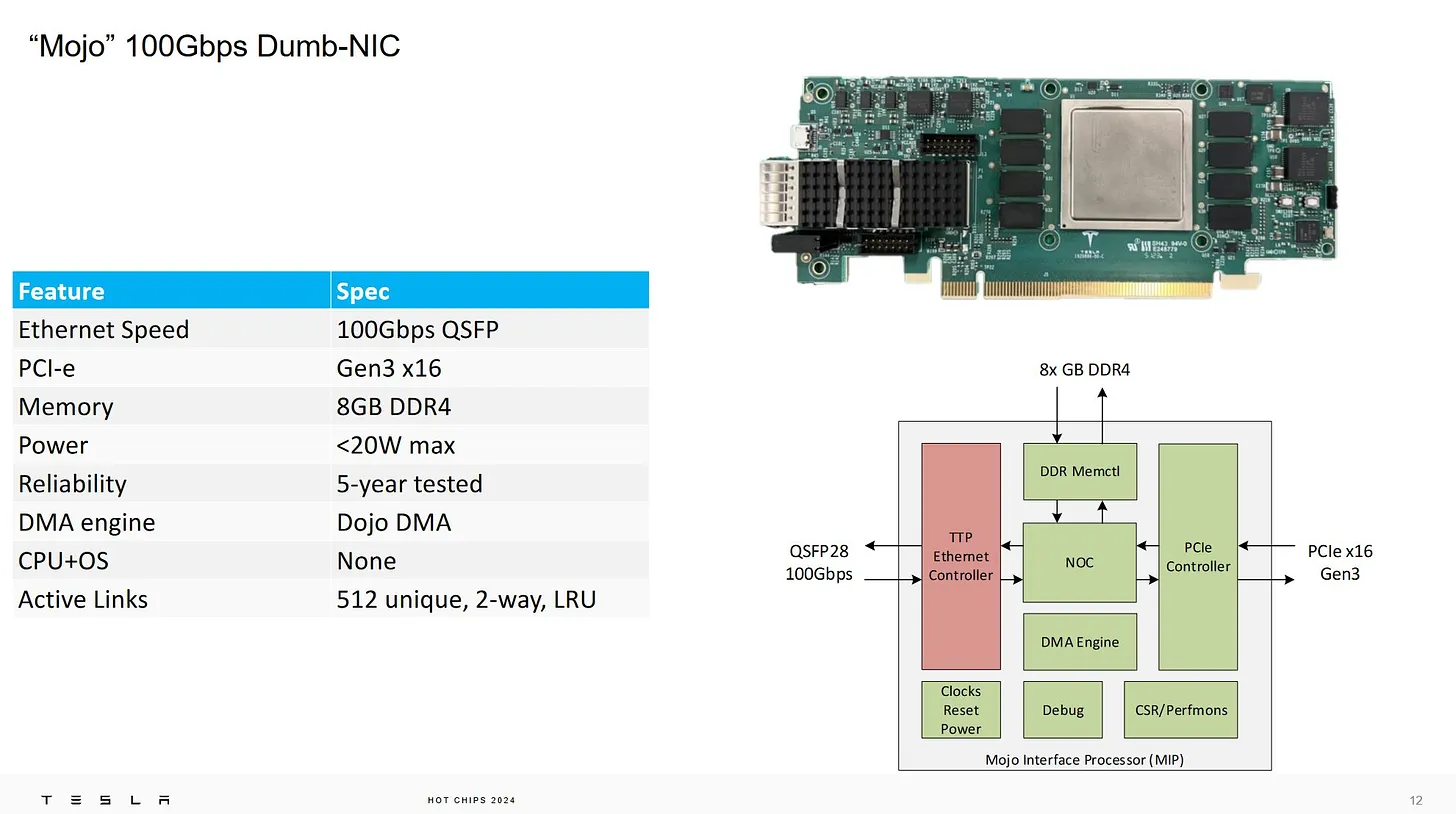
“Mojo” 100GB dumb-NIC (話說我以前做過的某 project 我叫 SmartXXX 呢)
中間這麼大一顆可能是 SoC 也可能是 FPGA ,我覺得 FPGA 的機率大一點,畢竟要改 code 這階段還是用 FPGA 穩定
CPU 的是用 Gen3 x16 和 8GB DDR4,Gen3 比較有趣,表示這真的是降成本達到目地
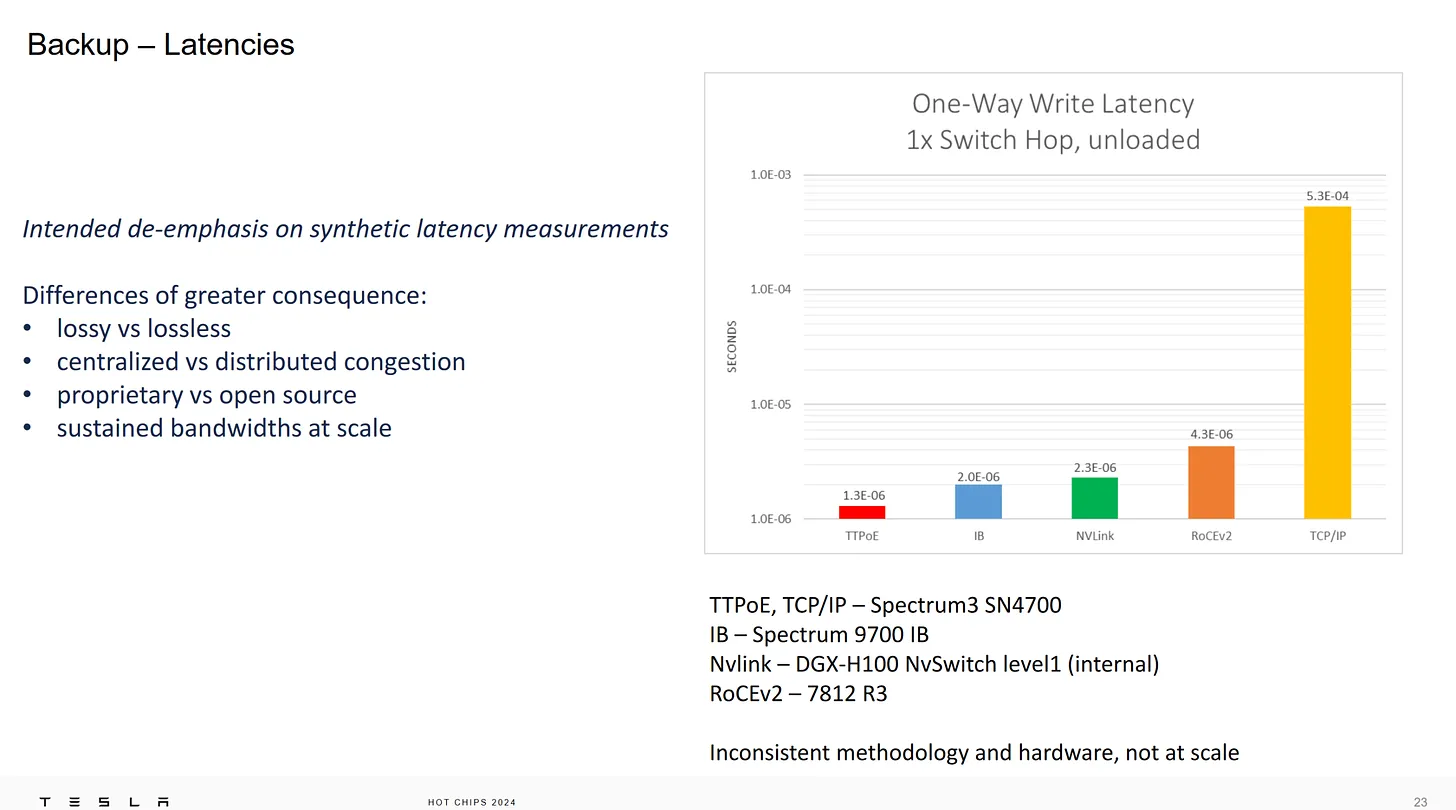
Latencies ,竟然 TTPoE 比 Nvlink 還快,Nvlink 已經算是對傳了,要過 ethernet 還比較快讓我難以想像
總結
我覺得技術細節透露有限,但是這個方向的確可以大幅減少 latency ,在網路的世界內,減少 latency 就是增加速率和效率,在頻寬固定的狀況之下
雖然相容性不佳,只是給 RDMA 用,但是我覺得仍不失為 intranet 上有趣的應用,而且的確很適合 DC 使用
ref. Github ttpoe Linux kernel 的 software 實作和規格, 要先有 software 才能搞 hardware 啊.

發佈留言