
[2023/12/13] Model 太多了,放一些覺得不錯的在這邊當筆記
Mixtral AI Mistral-8X7B-v0.1 : 雖然文內標要 100G GPU RAM,不過我用 CPU 不到 3G 就跑起來了,不知道是不是 llama.cpp 做了什麼事?
[2023/10/08] 新增 Chinnese LLAMA 2 部份
LLaMA是由Meta AI在2023年2月發布的大型語言模型。訓練了從70億到650億個參數的各種模型大小。
前一陣子試玩了一下,趁還有點記憶快點記錄一下記得的東西
大語言模型如果一般人要玩,最重要的前提是什麼都要大,要不然像 LLaMA 65B 就玩不動
如果是 65B 模型,硬碟最好準備至少 1T 最好 2T 的硬碟,因為還要加上轉檔,當然是用 SSD 才會快,原始檔 7B: 13G 13B 25G 33B(Meta 筆誤 30B ,都是通用的)61G,65B 122G,共約 220G
這是原始檔,還要加上轉檔的大小,以 7B 來說,Q4_0 大概 4G
如果是載入記憶體,記得大概 65B 就是 60G 記憶體,其他的部份和轉檔之後的大小差不多,如果是用 CPU 算,速度和 CPU 多少並不是線性的關係,並不是 CPU 愈多速度愈快
至於什麼是最佳值,我並沒有花時間找出來
llama.cpp 是此次拿來玩 LLaMa 的主要程式,採用 C++ 撰寫,目前應該支援 GPU ,但是以這種大模型最便宜的玩法都是 CPU ,所以具體要多少 GPU 不知道
精修大語言模型需要的資料更可怕,7B 精修的入門門檻是 16G VRAM 的顯示卡,目前市面上最便宜的 16G VRAM 顯卡應該是 4060 ,老黃應該是想這樣賣這些貨,這部份我就沒玩了
在一台 32 Cores 128G 的 ARM64 機器,30 Cores 運算出 token 的速度,13B Chinese llama 的速度大概是 550ms ,65B 原始的速度大概是 800ms 左右,這個會受問的問題影響
如果要用中文,Chinese-LLaMA-Alpaca 是好朋友,不過他們沒有放出精修過的模型因為授權因素,不過有熱心網友會在討論區釋出
目前 (2023/06/23) ,他們釋出了五個模型,7B/7B+/13B/13B+/33B
我用到現在是 13B+ 的結果最好,看了一下他們的論文發現不意外,等他們看有沒有 33B+ 的版本吧,不過 33B 我個人認為連英文的效果都不好,希望早點有 65B+ 的版本
至於精修記得他們至少是 8*A100 在跑,可能真的要很久,至於個人要玩精修看到這個資源量,還是謝謝再連絡了
後來 LLaMA2 釋出,該團隊釋出了 Chinese LLaMA Alpaca2 模型,我覺得品質好非常多,13b 的已經算可以用了,並且也不用再合成,方便很多.
Download
第一步是先 Download LLaMA 大模型,這邊有個 script 可以幫忙下載整理,經驗是,不見得能下載完成
我用中華電信 PPPoE 撥接是下載不完,但是固定 IP 是可以下載完的,所以如果無法下載記得換時間換條路看看
這邊採用的是 llama-dl script
cd llama.cpp/models curl -o- https://raw.githubusercontent.com/shawwn/llama-dl/56f50b96072f42fb2520b1ad5a1d6ef30351f23c/llama.sh
Compile
下載 llama.cpp 和 Chinese-LLaMA-Alpaca 放在二個不同的目錄
sudo apt install build-essentia pip install torch==1.13.1 pip install transformers==4.28.1 pip install sentencepiece==0.1.97 pip install peft==0.3.0 pip install protobuf==3.20.0 cd /nvme/llama git clone https://github.com/huggingface/transformers.git git clone https://github.com/ggerganov/llama.cpp git clone https://github.com/ymcui/Chinese-LLaMA-Alpaca cd llama.cpp make
Convert
剛剛用 llama-dl 下載下來的 models 需要轉檔,變成 f16 的模式,接下來可以從 f16 再轉成其他的格式
python convert.py models/7B/ (略) Wrote models/7B/ggml-model-f16.bin
轉檔完之後就可以用 quantize 轉成其他格式
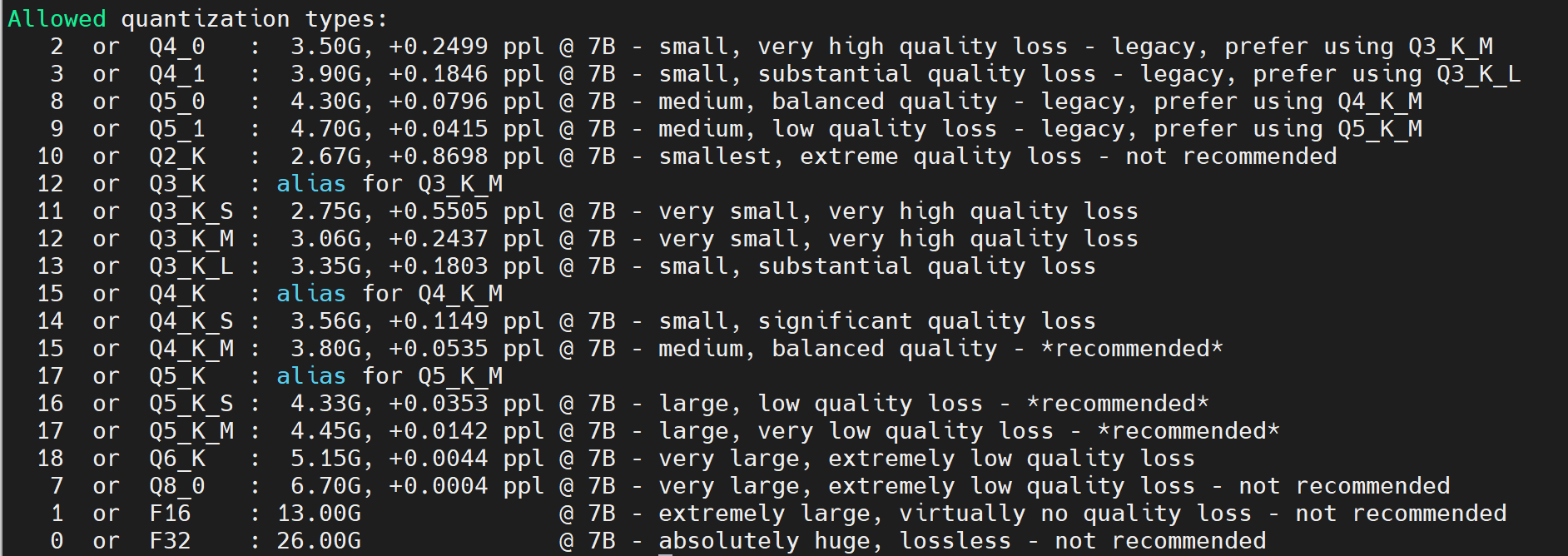
轉成我們需要的格式,來個簡單的 Q4_K_M 好了,跟據電腦的速度應該會花一分鐘左右
./quantize ./models/7B/ggml-model-f16.bin ./models/7B/ggml-model-q4_0.bin q4_K_M (略) [ 291/ 291] layers.31.ffn_norm.weight - 4096, type = f32, size = 0.016 MB llama_model_quantize_internal: model size = 12853.02 MB llama_model_quantize_internal: quant size = 3891.24 MB main: quantize time = 51255.05 ms main: total time = 51255.05 ms
馬上來測試一下
$ ./main -m ./models/7B/ggml-model-q4_0.bin -p "Building a website can be done in 10 simple steps:" -n 512
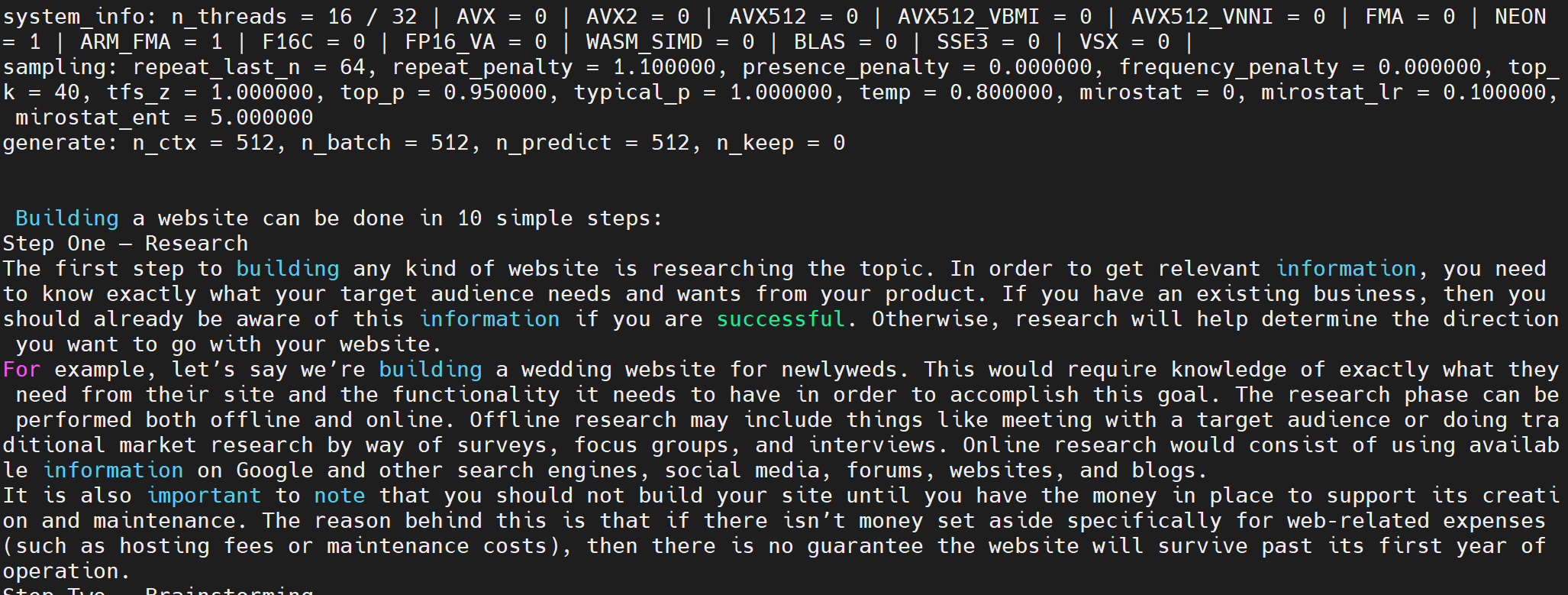
這中間請注意 system info 這一行,如果 CPU hardware support 沒有打開請記得檢查系統
system_info: n_threads = 16 / 32 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 0 | VSX = 0 |
Chinese LLaMa 2 Alpace 專案
上面的步驟只需要安裝相關 python 套件和下載 llama.cpp 即可,Chinese LLaMa 2 建議可以下載 alpaca 13b-16K 模型先試玩,這個交談的效果比較好
以下路徑和上一部份稍有不同,請自行腦補進行切換,不再說明
# 從 hugingface 直接下載模型 git lfs install git clone https://huggingface.co/ziqingyang/chinese-alpaca-2-13b-16k # 轉檔,會輸出 ggml-model-f16.gguf python llama.cpp/convert.py chinese-alpaca-2-13b-16k/ # 轉成 q5_0 (看起來品質和速度相對好的) llama.cpp/quantize chinese-alpaca-2-13b-16k/ggml-model-f16.gguf ./llama.cpp/models/alpaca-2-13b-16k-q5_0.bin q5_0
接下來就可以直接執行 demo 程式
$ ./main -m models/alpaca-2-13b-16k-q5_0.bin --color -f prompts/al paca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.1 -t `nproc` # 如果 CPU 太多,要限制在 numa 0 跑,本例限制 70 cores 執行 $ numactl -m 0 -N 0 ./main -m models/alpaca-2-13b-16k-q5_0.bin --color -f prompts/al paca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.1 -t 70
輸出是繁中,這個輸出品質還可以
Chinese-llama-alpaca 專案
Chinese-llama-alpacen 開源了中文LLaMA模型和指令精調的羊駝大模型。這些模型在原版LLaMA的基礎上補充了中文詞表並使用了中文數據進行二次預訓練,進一步提升了中文基礎語義理解能力。該網站已經將技術資料放在 Arxiv.org 上面 Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca.
我選擇用的是中文 Alpaca 模型,在說明內,合併需要動合拼中文LLaMA和 Alpaca 模型以及原始 LLaMA 模型,這邊只建議下載 7B Plus 和 13B Plus ,其他暫時沒有必要玩(註:除非出了 33B Plus or 65B Plus )
第一步,到模型下载下載需要的模型,我是放在 models 下,取名叫
ALPACA_7B_ZH/
ALPACA_13B_ZH/
LLAMA_7B_ZH/
LLAMA_13B_ZH/
合併模型
看命令就好了,code is instructions
# 7B model
python /nvme/llama/transformers/src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir models/ \
--model_size 7B \
--output_dir models-7b
python /nvme/llama/Chinese-LLaMA-Alpaca/scripts/merge_llama_with_chinese_lora.py \
--base_model models-7b \
--lora_model models/LLAMA_7B_ZH,models/ALPACA_7B_ZH \
--output_type pth \
--output_dir zh-models-7b
python convert.py zh-models-7b
# 13B model
python /nvme/llama/transformers/src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir models/ \
--model_size 13B \
--output_dir models-13b
python /nvme/llama/Chinese-LLaMA-Alpaca/scripts/merge_llama_with_chinese_lora.py \
--base_model models-13b \
--lora_model models/LLAMA_13B_ZH,models/ALPACA_13B_ZH \
--output_type pth \
--output_dir zh-models-13b
python convert.py zh-models-13b
這樣就大功告成了,那我們先來轉個 13b 的檔試試看效果如何?
./quantize ./zh-models-13b/13B/ggml-model-f16.bin ./zh-models-13b/13B/ggml-model-q5_0.bin q5_K (略) [ 363/ 363] layers.39.ffn_norm.weight - 5120, type = f32, size = 0.020 MB llama_model_quantize_internal: model size = 25177.25 MB llama_model_quantize_internal: quant size = 8933.81 MB main: quantize time = 106859.36 ms main: total time = 106859.36 ms
然後下個簡單的命令執行並且測試
./main -m zh-models-13b/13B/ggml-model-q5_0.bin --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.1 -t `nproc --ignore=2`

普普通通
33B
之前 33B 的中文頗差,最近更新了 33B 的 LLAMA Plus 和 ALPACA 33B Pro 模型,想說來試用一下是不是到堪用等級,以下是合併的命令
python /nvme/llama/Chinese-LLaMA-Alpaca/scripts/merge_llama_with_chinese_lora.py \
--base_model models-33b \
--lora_model models/LLAMA_33B_ZH,models/ALPACA_33B_ZH \
--output_type pth \
--output_dir zh-models-33b
# Convert to .bin
python convert.py zh-models-33b/
# use q5_0 as model
./quantize ./zh-models-33b/ggml-model-f16.bin ./zh-models-33b/ggml-model-q5_0.bin q5_0
其他
如果碰到類似以下的訊息,或是許法讀取 model ,請檢查 model 的 md5 checksum 是否正確,另外也將 llama.cpp 升級(或是降級),或是不要使用某些支援,我曾經碰過類似的問題,重新編譯時拿掉對 OpenBIAS 就好了
Unexpected Termination due to std::runtime_error during model load in llama.cpp
希望這篇對有興趣的人有些小幫助可以快速進入這個世界(然後快速的逃走)

發佈留言