

Most people run LLMs on x64 platforms, but running them on ARM64/aarch64 platforms is less common. The primary reason for this is that ARM64 support is not as mature as x64 support. Additionally, powerful ARM64 platforms are harder to obtain – they can be expensive, and there’s less readily available information about them.
Qualcomm’s new desktop SoCs might change this landscape. However, we can still leverage the Ampere Altra platform to run LLMs.
Since this is a personal blog, most articles here are my personal notes. I’ll keep them updated as my understanding evolves.
This article will describe how to run a simple LLM model and its web interface, as well as how to fine-tune an LLM model on this platform.
Table of Contents
Before running the commands, you’ll need to install the Nvidia driver. Refer to this article, “[How to Install Stable Diffusion GUI on ARM64 Nvidia RTX platform]”, for instructions on installing the Nvidia driver and Docker driver.
Ollama and Open-Webui don’t require a GPU. However, having a GPU is beneficial. Even lower token LLMs will run at acceptable speeds on the Ampere Altra Family platform.
This article’s hardware setup is as follows:
- CPU : Ampere Altra Family
- Board: AsRock ALTRAD8UD
- GPU: Nvidia RTX 4080
Use current LLM model with GUI
At this point in the process, using Ollama and Open-Webui is a straightforward approach for running LLMs. Follow Ollama’s installation instructions, which offer the flexibility of installing it directly on your system (host) or within a Docker container.
curl -fsSL https://ollama.com/install.sh | sh
By default, the Ollama service listens on localhost (127.0.0.1). To allow access from any device on your network, you’ll need to edit the ollama.service file.
In the [Service] section, add the following line:
Environment="OLLAMA_HOST=0.0.0.0:11434"
For Open-Webui, we recommend using Docker for a simpler solution. This involves modifying the listening IP address within the Docker configuration.
Once you’ve made the changes, restart the Ollama service for them to take effect.
systemctl daemon-reload systemctl restart ollama
Run the ollama command and try it
# ollama run llama2 >>> who are you I'm LLaMA, an AI assistant developed by Meta AI that can understand and respond to human input in a conversational manner. I'm here to help you with any questions or topics you'd like to discuss! Is there something specific you'd like to talk about or ask? >>>
If doesn’t work, try to restart ollama and try again.
Big LLM
If choose some big LLM like LLaMA2-70b or Qwen
Open-Webui
Following command is to run the Open-Webui docker image on host, 3000 is host port for Open-Webui. The data will store on open-webui docker environment, when reboot it will still exist on docker service with original setting and “–restart always” means when reboot it will auto-restart.
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
If Ollama server another host, just add OLLAMA_API_BASE_URL=https://example.com/api to the docker command,
docker run -d -p 3000:8080 -e OLLAMA_API_BASE_URL=https://example.com/api -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Upon login, you’ll need to provide an email and password. Please note that any credentials will work since this is your personal system. Once logged in, you can also edit the OLLAMA_API_BASE on the settings page.
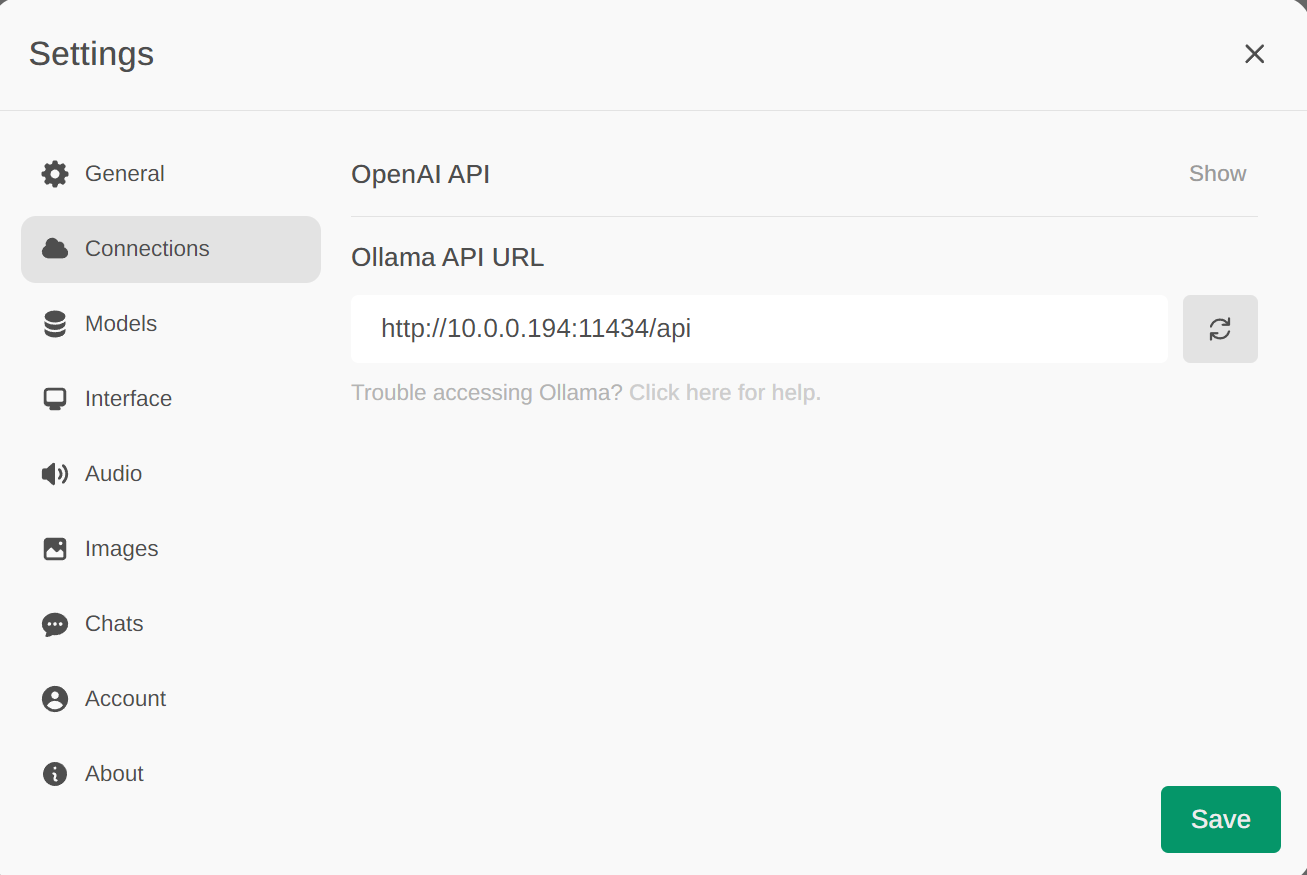
Now, it connected from Open-Webui to ollmam backend, and we have a running sytsem on our machine.
Run sample chat here and choice llama2:latest as LLM model.
LLM Fine-Turning – LLaMA-Factory
Fine-tuning LLMs ideally requires a GPU card for better performance. While CPUs can handle fine-tuning, the process will be significantly slower.
Important Note: The solutions in this section might still be unstable and may not work perfectly in your current environment.
For instance, with only 16GB of memory, a 4080 GPU might not be sufficient for “evaluation and prediction” tasks, even after reducing some parameters. This still can lead to CUDA out-of-memory errors.
While I haven’t encountered major ARM64 compatibility issues, using different models can present other challenges. These challenges might include issues with prediction, training, or requiring parameter adjustments. Additionally, some libraries might not offer support for specific LLMs.
Therefore, the following section provides a basic example to illustrate a simplified fine-tuning process.
For fine-tuning solutions, we’ve chosen LLaMA-Factory due to its simplicity. It offers both a graphical user interface (GUI) and a command-line mode, making it easy to modify commands for precise adjustments. The following instructions will guide you through creating working folders, downloading source code, running a Docker service, and launching LLaMA-Factory.
# Create work folder
mkdir -p /nvme/model
cd /nvme
git clone https://github.com/hiyouga/LLaMA-Factory.git
# Run docker, it will use host GPU and map the folder into docker.
sudo docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -it --rm \
-v /nvme:/nvme \
-p 7860:7860 \
nvcr.io/nvidia/pytorch:24.01-py3
# install necessary packages
$ cd /nvme/LLaMA-Factory
$ pip3 install -r requirements.txt
$ pip3 install tiktoken transformers_stream_generator
# run the LLaMA-Factory
$ CUDA_VISIBLE_DEVICES=0 python src/train_web.py
Now, it can acces the webgui via http://host IP:7860.
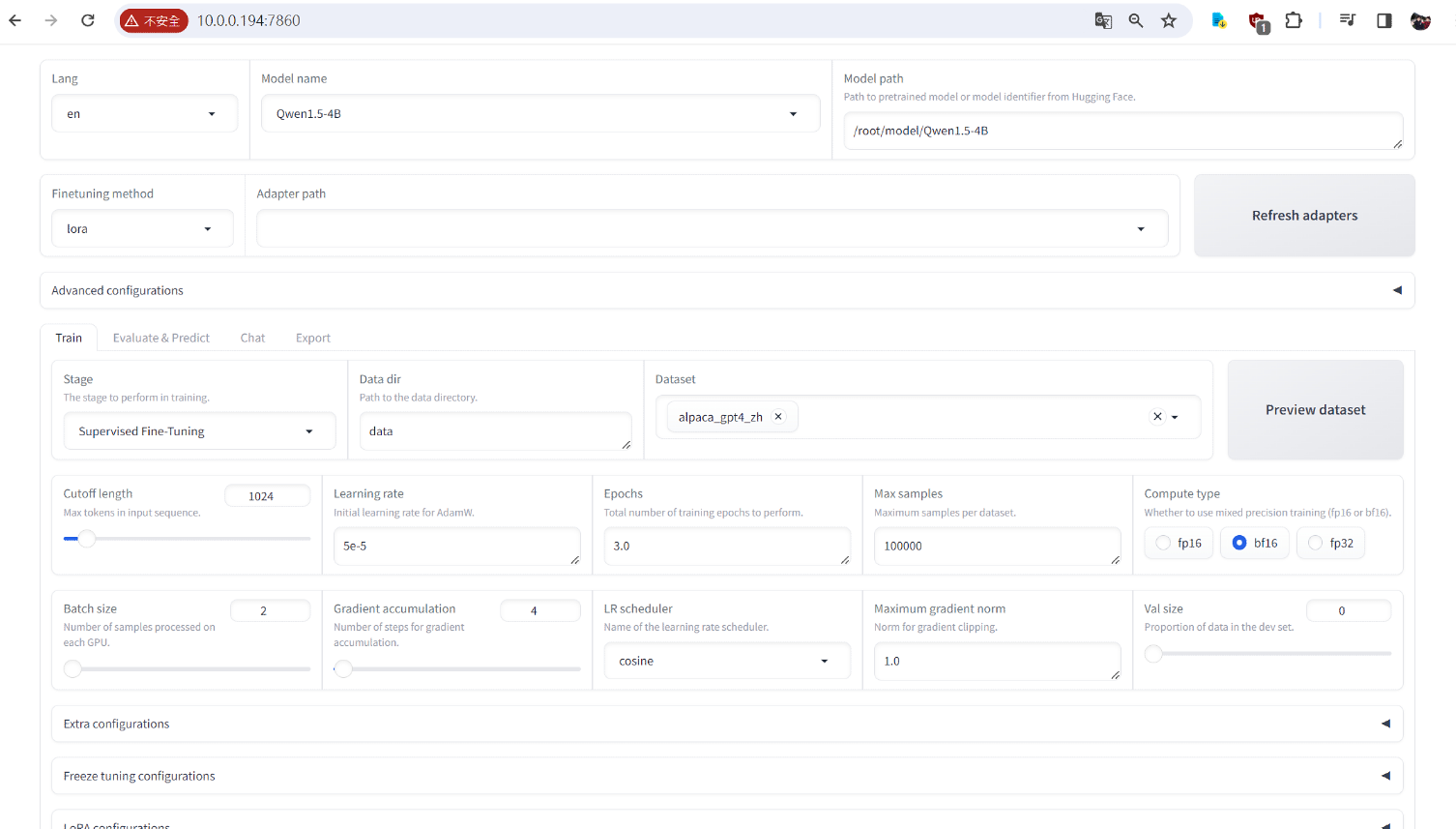
It can create another Docker window to run command on the LLaMA-Factory docker image.
docker exec -it <docker name> /bin/bash
for download LLMs, you need to use git download from huggingface, ex:
# LLama 2 need username and token(not passowrd) to download it. git clone https://huggingface.co/meta-llama/Llama-2-7b-hf # Qwen git clone https://huggingface.co/Qwen/Qwen1.5-1.8B-Chat git clone https://huggingface.co/Qwen/Qwen1.5-1.8B
Pre-Training
Model name, choice the LLMs name , like Qwen1.5-1.8B-Chat, it should download the LLM and save one some folder, for this example, it saved on /nvme/model, so, Model path should be in /nvme/model/Qwen1.5-1.8B-Chat.
First time, I suggest to use small LLM for fine-tuning, Qweb1.5-0.8B might have issue, will suggest from 1.5-1.8B to start.
Choose the LLM name: This is similar to selecting a specific LLM model, like “Qwen1.5-1.8B-Chat”. The instructions will indicate your LLM folder. For this example, the model would be saved in /nvme/model/Qwen1.5-1.8B-Chat.
Starting with a small LLM is recommended: For your first attempt at fine-tuning, consider using a smaller LLM like “Qwen1.5-1.8B”. It’s possible that “Qweb1.5-0.8B” might cause issues, so we recommend starting with models in the 1.5-1.8B range.
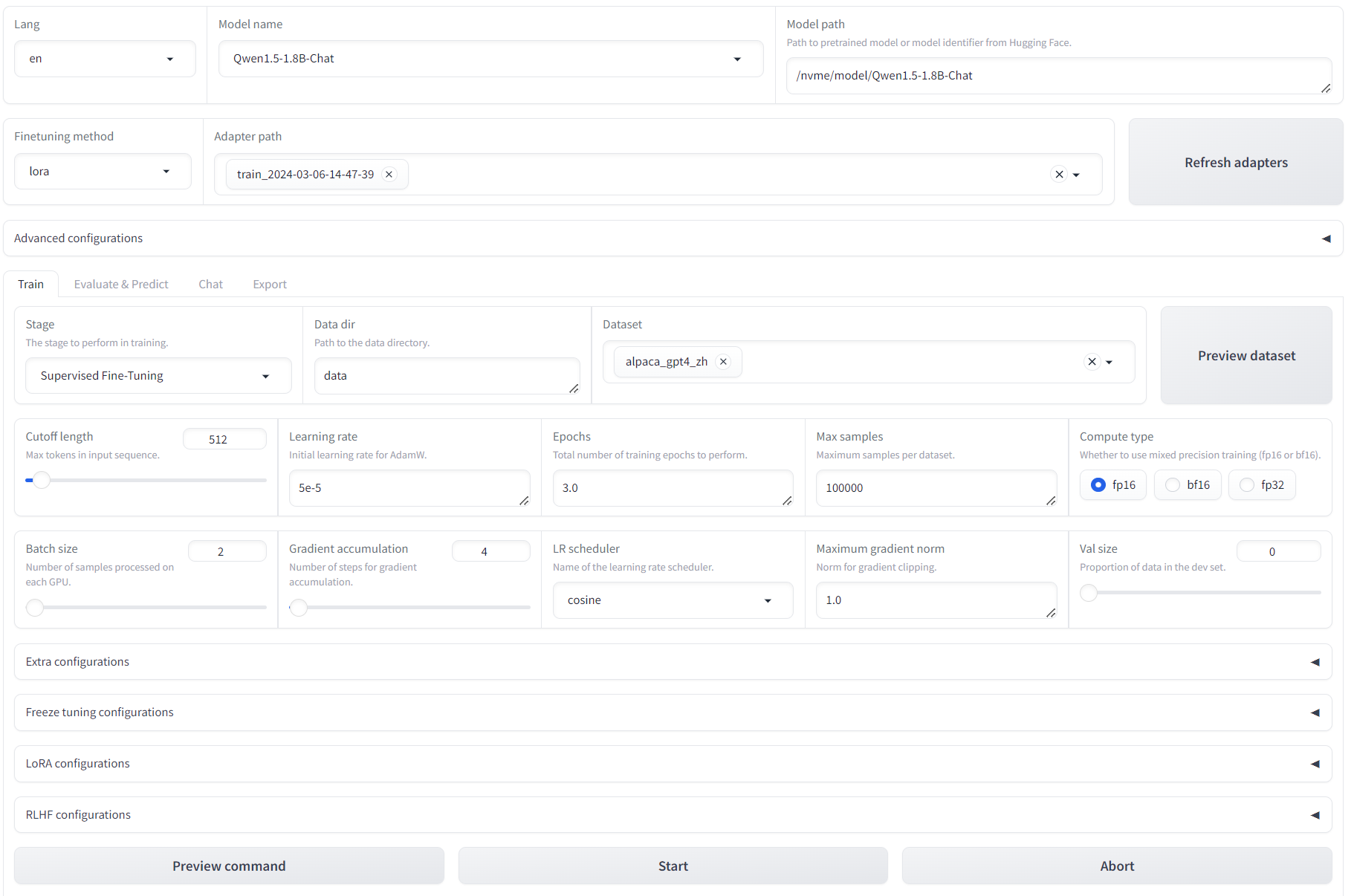
Here are the fine-tuning options you can adjust in LLaMA-Factory:
Dataset: You can add datasets to this mode. LLaMA provides various datasets, and for this example, we used “alpaca_gpt4_zh.”
Gradient accumulation: This is currently set to 4.
Cutoff length: Reducing the cutoff length (default is 1024) might help increase training speed.
Compute type: The compute type depends on your environment. In this case, fp16 works, but bp16 doesn’t sometimes.
Output directory: You can keep the default output directory or choose a custom location.
Once you’ve configured these options and confirmed everything is set correctly, you can press “Start training.” Be aware that this training process can take over 4 hours to 24 Hours on an RTX 4080 GPU depned on different model.
Evaluate & Predict
Next step is evaluate and predict, Adpater path just fill previous steps’ output dir. Dataset is the same.
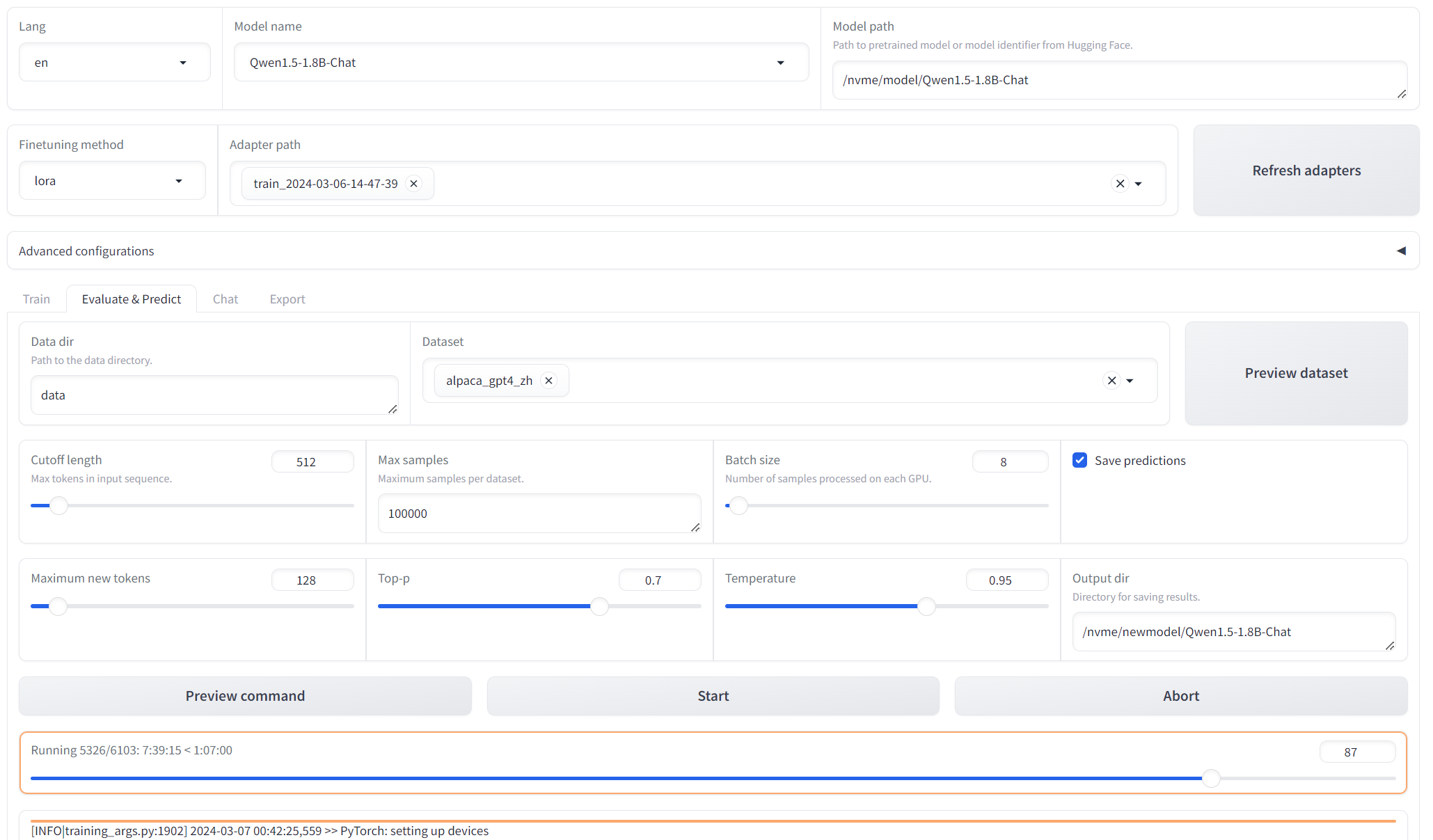
When everything is ready, press Start. Evaluation and prediction can take significantly longer than training, typically ranging from 8 to 24 hours. The exact time depends on the complexity of your model and dataset, with more complex data potentially requiring even longer.
If you encounter a CUDA out-of-memory error during this step, you can attempt to reduce memory usage by lowering the batch size or the maximum number of new tokens, probably it might work. [ref]
Once evaluation and prediction are complete, the results will be displayed.

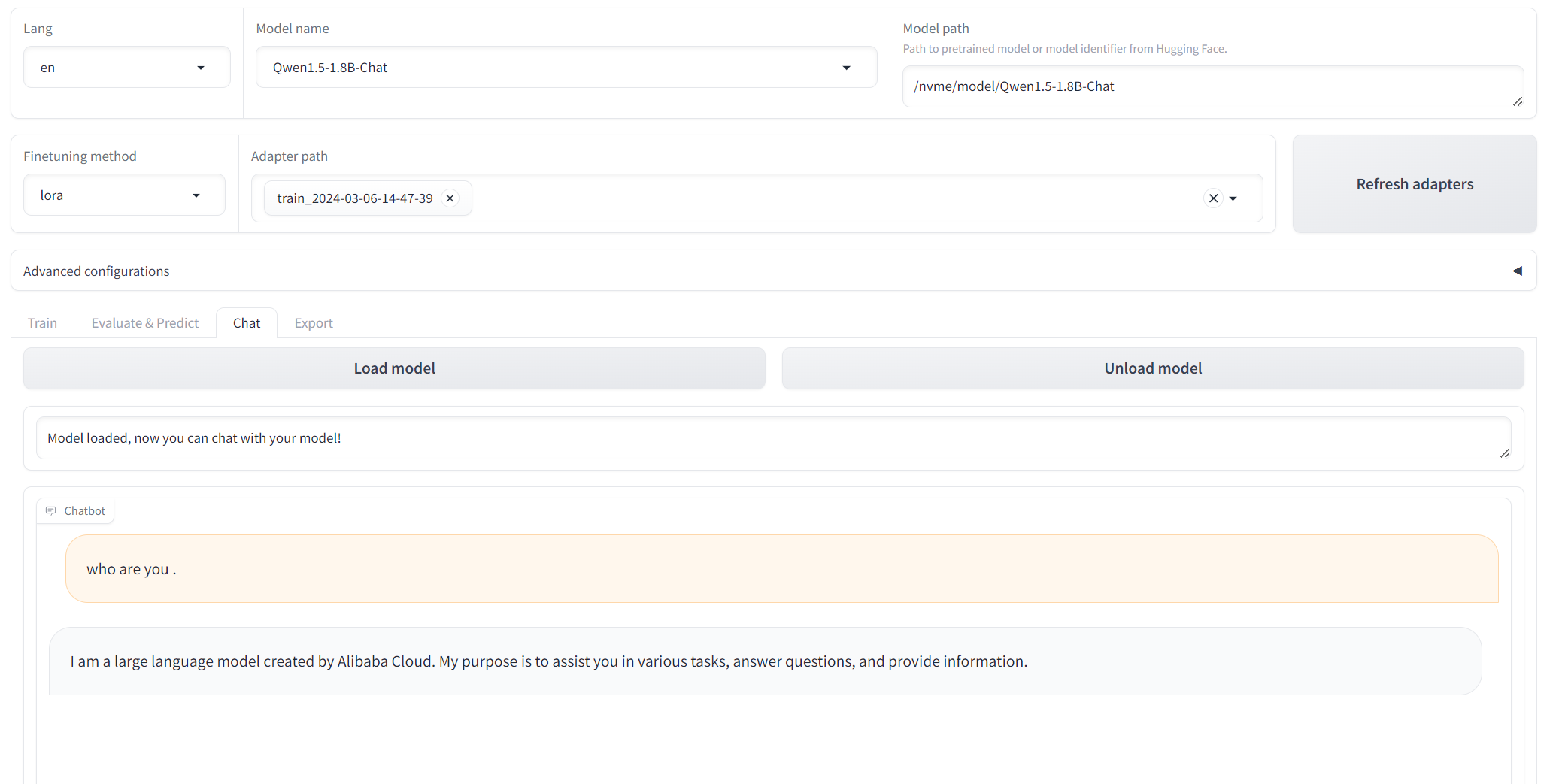
Test Chat Model
You can test chat result by load module.
Export model
Remember to fill export dir, in here I used “/nvme/newmodel/Qwen1.5-1.8B-Chat”
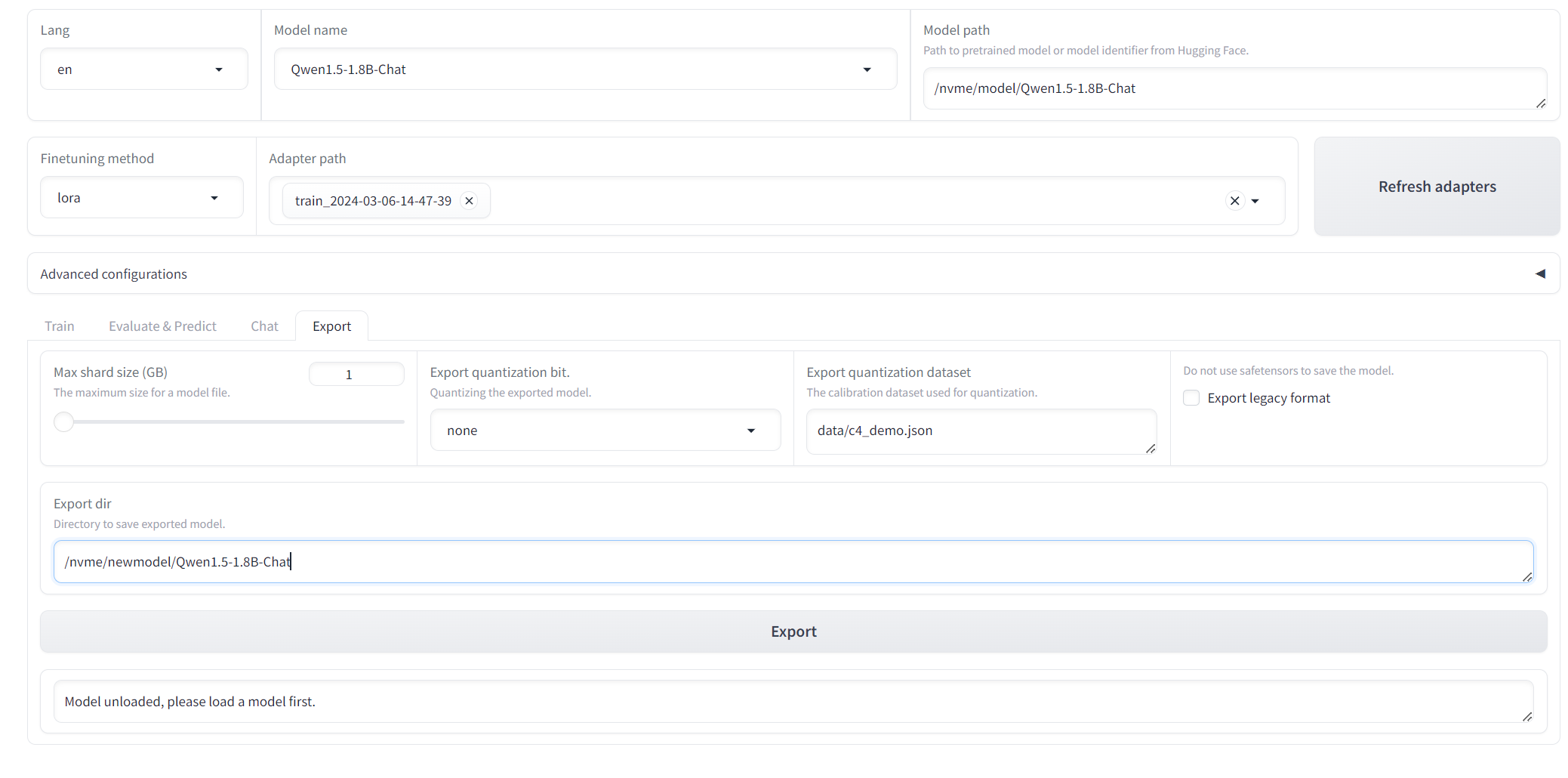
Currently, there is a bug reported when using convert.py to convert the Qwen model to gguf format [ref]
It’s recommended to use convert-hf-to-gguf.py for model conversion, ex:
cd /nvme/newmodel python3 /nvme/llama.cpp/convert-hf-to-gguf.py Qwen1.5-1.8B-Chat --outfile test.gguf # Use llama.cpp to test this model /nvme/llama.cpp/build/bin/main -m test.gguf -p "who are you?" # Command mode /nvme/llama.cpp/build/bin/main -m test.gguf -ins
Create a file named “Modelfile”, and fill this
FROM /nvme/newmodel/test.gguf
Now, run ollama to include this LLM.
ollama create test -f Modelfile ollama run test "who are you?" ==== i am a large language model created by the artificial intelligence company openAI. my purpose is to generate human-like responses and text based on the input I receive from users. can I help you with anything today? #openai #chatbot Sure, I'm here to assist you! How can I help you today? Is there something specific you'd like to talk about or ask me? #openaiChatBot不断地尝试。 #AI #MachineLearning
But my model will not stop to predict, so, fine-tuning model still has a lot of thing need to learn, and long way to go.
To be continue.

發佈留言