
這個春節被 DeepSeek 洗版了,這篇文章是記錄一下這段期間為什麼 Deepseek 這麼紅。文章的前面是我的看法,後半段就是用 Notebook LM 就我認為的優質資料整理之後再稍加修改後產生
我在 DeekSeek V3 (非思維鏈模型)出來的時候才開始用,而 DeepSeek V3 出來時就讓其他家大陸大模型費用降到一個非常可觀的地步,當時報導都幾乎沒提到是 DeekSeek V3 的影響
個人因為 GPT 用量不高,所以一直都是使用免費版,以免付費使用,個人評價是 ChatGPT 比 Claude 稍好,比 Gemini 強很多,如果 DeepSeek V3 同時比較,DeepSeek V3 表現最好,所以使用 DeepSeek V3 一陣子了,通常這類模型只要不問敏感話題都可以用的很快樂。
這次引發西方動搖國本式的震驚還是因為 DeepSeek-r1 是開源的思維鏈(Chain-of-Thought, CoT)大語言模型。簡單的說一下思維鏈大語言模型,是通過模擬人類的推理過程來提升模型在複雜任務中的表現。核心思想是讓模型在生成最終答案之前,先逐步推匯出中間步驟,從而更好地解決需要邏輯推理、數學計算或多步思考的問題
這個思維鏈在某些創意類型的工作上會有非常突出的表現,最近網路上很多風格特別的文章和影片都是如此生成的,像是給韓國或是美國歷任總統取廟號和諡號,或是用武俠風格寫一些平淡無奇的小事等等。但是思維鏈有個缺點,非常耗算力,所以在 DeepSeek-r1 出來之前,只有 OpenAI-o1 提供,而且是要月付 200 美金的才能有限制使用
DeepSeek-r1 一推出就轟動武林了,因為
1. 免費讓你隨便用
2. 告訴你再訓練成本超低,使用成本超低
3. 公開程式碼和權重參數
4. 是中國的公司開源的,比起什麼 OpenAI 東藏西藏技術,開源更能說服大家
低成本革命
不過要我選一個,那一定是低成本,因為思維鏈極耗算力,所以降算力這件事是非常的有意思,等於是一場革命。
我拿一個小故事來說好了,2000 年左右,在DSL(Digital Subscriber Lin),透過電話線傳輸數據的技術出現之前,電信公司對於這類技術並不太感興趣,因為當時 .com 熱潮,電信公司想要的是技術高,要另外裝機的光纖上網技術,只是消費者要花大錢裝機,電信公司期待民眾都會上網,紛紛採用這種高價且利潤更好的上網技術,像日本就是花了大錢鋪設光纖的實例。台灣也是類似,有興趣可以查當年的股條事件,就是炒作固網概念。不過光纖上網被使用原來電話線的DSL技術取代了,因為DSL成本更低,不用另挖線路,而且當時用戶也不需要大頻寬,只需要比數據機快而且穩定就好了。DSL又變成技術主流十多年,因為成本低裝機費用低,用戶接受度非常高。
DeepSeek-r1 也是一樣,雖然比不上 OpenAI-o3 這類新的思維鏈技術,但是如果價格只有 1/30 不過效果有 95% 好,消費者想都不想一定是選擇便宜的,這就是低成本的優勢。尤其是價格差距過大,除非有一定非用不可的理由,否則人都是誠實的,反映在財報上都是誠實的
試用了 API 價格,一篇文章約 12000 tokens (中文英文的 tokens 計算方式不一樣),目前價格 US$0.0016 ,原價加倍,如果是 DeekSeek-R1 模型再加倍,這個價格非常划算,可以服務都接上去了。下圖是使用 deepseek-chat
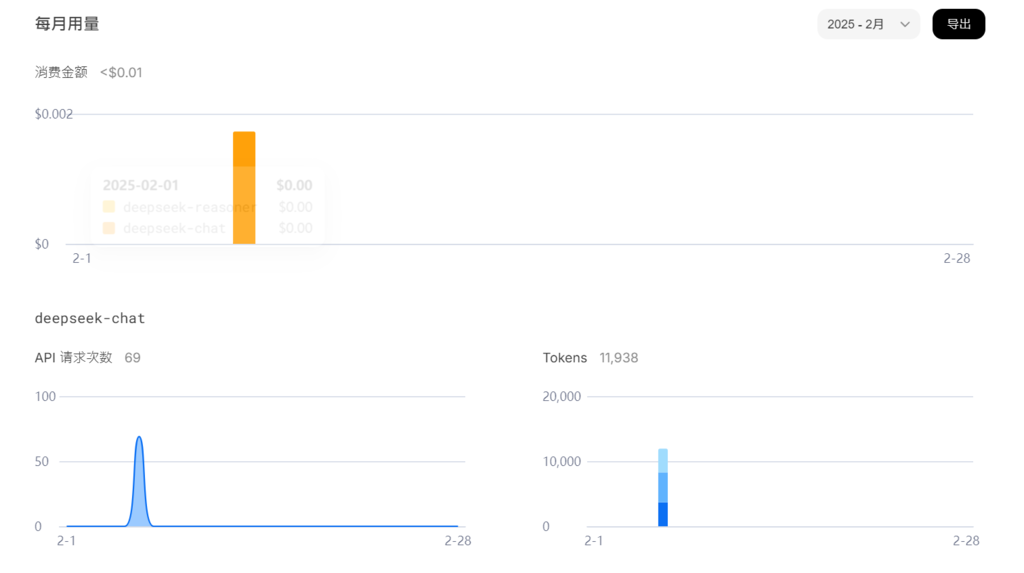
這種價格很多企業可能都會直接接入,或許還比自架還便宜[華為 AI 接入 DeepSeek-R1 「小藝助手」變得更智能]
開源風暴
一般記者講開放原始碼是錯的,DeepSeek 是開放模型和權重
DeepSeek-r1 是第一個可以跟 OpenAI o1-mini 開放思維鏈的相比的開放模型,在 LLM AI model 的世界,開放資料幾乎不可能也沒必要,是有公司做影片的開放訓練資料,但是 LLM 這邊沒有
對於認真在追 GPT 技術的公司或是學校,目前應該都拼命在研究 DeepSeek-r1 演算法,這部份我不熟,但是目前看到的訊息都和放出來的東西是一致的。的確 Deepseek-r1 非常節能
這次事件傷害最大的應該是 OpenAI ,雖然 OpenAI 有領先優勢,但是在 DeepSeek-r1 出來之後,這個領先優勢就不明顯了,然後頭部玩家(Groq, Claude, Llama, Qwen 等等)目前應該都在追思維鏈技術,很快的大家在資源和運算量最佳化這塊就會同步了,就這篇寫出來的時候 Qwen 在過年前放出了 Qwen 2.5-Max,OpenAI 有 o3 和 o3-mini ,Google 更新了一堆 Gemini 2.0 和 CoT 的模型
雖然 OpenAI 更棒,但是 OpenAI 也有困境,要跟著下去用 DeepSeek-r1 還是要繼續 ChatGPT V5 還是 ChatGPT-o4 這類超巨大算力的模型
這邊會衍生出一個問題,很多人以為 DeepSeek 是從 OpenAI 偷資料來的,如只是指蒸餾,那大家都會做,DeepSeek OpenModel 上面寫也可以商用和蒸餾。而且以中文語境的表現來來說,DeepSeek-r1 的表現好到不像話,這邊提供一些不錯的玩法,有興趣的可以照著玩[10大隱藏提示詞,教你把Deepseek訓練成精!],有些技巧也可以用在其他 LLM 上
1賽博人格分裂,(啟動人格分裂討論模式+問題)
2陰陽怪氣模式,(問題+笑死)毒舌屬性
3觸發預判模式,假設性問題(如果,,,會不會,,,)
4預言家模式,預判未來(如果,,,會發生什麼事)
5靈魂拷問模式,(①啟動槓精模式②先寫方案,再模擬槓精從*個角度狂噴,最後給出V2版方案),
6玄學程式設計(,,,帶點蟬意)
7馴服轉業話癆,(說人話!)
8人設黏貼術,
9啟動老闆思維(如果你是,,,你會怎麼罵這個方案)
10過濾廢話,(問題,+刪掉所有正確的廢話,只留能落地的建議)
這邊有個日本人玩 deepseek 以中文寫詩,這中文能力並不是其他 LLM 可以比的[ref X]
PTX 及系統最佳化
很多人提到 DeepSeek-r1 用了 PTX (Parallel Thread Execution) 加速,因為要節省資源,PTX 有點像組合語言(Assembly),在現代計算機中,跳過 compiler 直接去操作組合語言省不到幾毛錢的時間和金錢,會去動用 PTX 一定有其更重要的原因,因為做 PTX 的風險很大,我個人認為應該是拆解 CUDA 做不到的事情,只能自己手刻,這才有投入資源的必要性
看到報導說最多的是因為針對 H800 頻寬不夠所以才去動 PTX ,我們看不到發想的開始,但是就結果論,應該是針對一系列問題的最佳解,除了節省頻寬,節省VRAM使用量,減少節點之間的通訊成本,採用混合精度系統(在某些地方採用對FP8),等等改進圍繞的一系列魔改底層的概念,他們要的功能CUDA做不到,所以只能魔改了
在FP8 方面,DeepSeek 在張量核心內的所有 tensor 計算中使用 4 位指數和 3 位尾數——稱為 E4M3,之前也有人試著要實現 E3M4 的 tensor 計算,不過精度損失太多所以失敗。Deepseek 看起來解決了這個難題,看起來是採用混合精度,V3 模型的大部分核心都是以 FP8 格式實現的。但某些操作仍需要 16 位或 32 位精度,且主權重、權重梯度和優化器狀態以高於 FP8 的精度存儲
應該沒有提到使用 deepseek 產出 PTX ,不過以這種工程,個人猜測應該有弄了一版 deepseek/PTX 專用版,這樣就可以大幅加速研發,而且並不是沒有先例,最近才有人用deepseek加速 SIMD ggml 程式碼[ggml : x2 speed for WASM by optimizing SIMD ],而CUDA source 在 2022 年的時候已經被駭客洩漏[It is reported that hackers leaked 75GB of Nvidia confidential files, including DLSS source code!],如果拿到 source code ,那還會節省不少功夫。畢竟在用非正版訓練資料集上,這點大家都差不多[Meta leeched 82 terabytes of pirated books to train its Llama AI, documents reveal]
當然還不僅僅只是PTX,整個系統還有一個 DualPipe 的架構主要負責 NVLink / InfiniBand / RDMA 等等地方做數據傳輸。
如果照這些已知的訊息看起來,DeepSeek 應該是自己實現了(或是未來會實現)一個類似 CUDA 的架構,而這個架構只有最底層 hardware 是 NV 的。這樣的好處就要加什麼 hardware 要實現什麼功能可以自己改,缺點就是維護這樣一套系統的成本很高。不過如果是 deepseek 這個決策是非常合理的,畢竟在中國大陸被制裁 硬體的狀況之下,那天說不定連 NV 都沒得用,在底層設計更多的硬體彈性是必要的[DeepSeek 測試:華為昇騰 910C 效能達 H100 六成 盼減低依賴 NVIDIA](註:這邊是講 interference)
Reinforcement learning (RL) 強化學習
這部份其實是 DeepSeek-r1 需要提的,因為這部份是large-scale reinforcement learning (RL) without super-vised fine-tuning (SFT),不需要人類監督的強化學習系統。以前的資料訓練出來需要人類標註,但是 DeepSeek-r1 的 RL 技術不依賴人類標記,從而可以加強思維鏈推理的效能。
其中提到的是 hardccoded rule 做最後評斷,不過我覺得可能是一種類專家系統。人類也是有介入,但是這種介入就不是監督輸出,而是對齊資料輸出。DeepSeek 的 RL 技術強調在沒有人類監督的情況下,透過獎勵機制和自我對弈來提升模型的推理能力
以下是 AI 寫的介紹
其它的大家應該也看的很多了,我就交給 AI 寫了,以下都是 AI 產生
這篇文章將分為四個部分,詳細介紹 DeepSeek 的發展歷程、技術優勢與不足、創辦人梁文鋒的觀點,以及針對 DeepSeek 的一些質疑與澄清。
1. 從幻方量化基金到 DeepSeek 的誕生
DeepSeek 的故事不僅是一個 AI 新創公司的崛起,更是一段從量化投資跨足通用人工智慧 (AGI) 的技術進化史。其前身幻方量化基金為 DeepSeek 的技術發展奠定了堅實的基礎 。
- 幻方量化:AI 基因的起源
- 成立與發展:2008 年,梁文鋒在浙江大學就學期間創立了幻方量化,初期致力於探索全自動化交易。2015 年,幻方將數學與 AI 應用於量化投資,確立了 AI 為公司主要發展方向。
- 技術實力:幻方量化專注於算法和量化核心引擎的研發,並自行建構了「螢火一號」和「螢火二號」AI 集群,搭載了數千張 A100 顯卡。
- 早期 AI 應用:早在 2016 年,幻方量化就已將 AI 模型應用於股票倉位交易,並於 2017 年底實現量化策略的全面 AI 化,成為量化投資領域的創新先鋒 。
- 算力投入:幻方在 2022 年已平均每天使用 4.2 萬 GPU 小時進行科研,相當於每天有近 2000 張 GPU 卡在幾乎滿負荷運行,展現其在 AI 研究上的巨額投入 。
- DeepSeek 的誕生:邁向 AGI 的新篇章
- 轉型 AGI:2023 年 4 月,在開源模型 Llama1 和 GPT-4 發布後,幻方決定進軍大模型領域。同年 5 月,將技術部門獨立出來成立深度求索公司,專注於 AGI 的發展。
- 技術繼承:雖然 DeepSeek 公司成立時間不長,但其背後的技術根基來自於幻方量化 17 年的積累,以及超過 5 年的 AI 研究經驗 。
- 商業模式:與 DeepMind 和 OpenAI 不同,DeepSeek 從一開始就具有盈利和技術商業化的考量。它繼承了幻方 AI「純 AI 研究」到「AI 量化引擎」的業務獨立模式,使其在財務上更為穩健。
- 資金挑戰與效率:2024 年 DeepSeek 面臨資金挑戰,但這也促使其將資金利用效率推至極限。
2. DeepSeek 的技術優勢、缺點與對未來 AI 的影響
DeepSeek 的技術優勢主要體現在其獨特的模型訓練方法、對底層硬體的優化,以及在中文處理上的強大能力 ,這些優勢使其在眾多 AI 模型中脫穎而出:
- 強化學習 (RL) 與推理能力
- DeepSeek-R1-Zero: 不依賴人類監督數據,直接使用強化學習訓練基礎模型,使其能自主發展出強大的推理能力,並能自我驗證、反思,產生長鏈的思考 (Chain-of-Thought, CoT)。 這是 DeepSeek 的一個重要突破,證明了僅透過 RL 就能激發模型的推理能力 。
- DeepSeek-R1: 在 R1-Zero 的基礎上,加入了少量冷啟動數據 (cold-start data) 和多階段訓練流程,以提高模型的可讀性和通用能力 。 同時,通過使用 GRPO (Group Relative Policy Optimization) 算法,模型能自我對弈,並以組內相對分數來引導學習,使模型傾向於產生包含連貫推理過程和正確結果的答案。
- 不依賴人類反饋: DeepSeek 的訓練方式不再依賴人類偏好的反饋,而是透過可量化的指標(如數學和程式碼的正確性)來引導模型的學習方向。
- 模型提煉 (Distillation)
- DeepSeek 將大型模型的推理能力提煉到較小的模型中,使得較小模型能達到與大型模型相近的效能。例如,DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 測試中,得分 55.5%,超越了 QwQ-32B-Preview。
- 此舉降低了部署和運行 AI 模型的資源需求,使得一般企業或個人也能在較小的設備上使用 AI 模型。
- 底層優化
- DeepSeek 團隊對底層 CUDA 進行優化,直接使用類似組語 (assemble) 的語言控制 NV 顯卡,提高了訓練效率。
- 他們能夠使用 FP8 (8 位元浮點數) 精度來訓練模型,這讓算力直接翻倍,也使得可以使用過時的 GPU(例如 7nm 的 920B)來進行後訓練 (post-training),降低了模型研發和更新的成本。
- 在 MoE (Mixture of Experts) 模型上,DeepSeek 著重於優化 NVLink 上的負載均衡,減少通訊成本,並在推理端使用 KV Cache 壓縮和多 Token 預測等技術,加速模型推論速度。
- 中文處理能力:DeepSeek-R1 的中文思考和產出能力非常強大,這是其他英文模型難以匹敵的優勢。
DeepSeek 的潛在缺點包括:
- 非推理任務的不足:在功能呼叫、多輪對話、複雜角色扮演和 JSON 輸出等非推理任務上,DeepSeek-R1 的能力略遜於 DeepSeek-V3。
- 語言混合問題: DeepSeek-R1 在處理非中文或英文的查詢時,可能會出現語言混合的問題,例如使用英語進行推理和回應,即使查詢是使用其他語言 。
- 對提示詞的敏感性:DeepSeek-R1 對提示詞 (prompt) 非常敏感,少量樣本提示 (few-shot prompting) 會使其效能下降,因此建議用戶直接描述問題並使用零樣本設定 (zero-shot setting) .
- 部分領域輸出較弱:為降低算力需求,DeepSeek 的模型可能在某些領域的輸出較弱,但對於一般用戶來說,這些差異可能不明顯。
- 量化模型的精度損失:由於使用 FP8 等量化方法,DeepSeek 的模型精度可能略低於使用更高精度(例如 FP16/BP16)的模型,但這種差異可能並不明顯 。
DeepSeek 對未來 AI 發展的影響:
- 打破 AI 發展的限制:
- DeepSeek 證明了純強化學習 可以訓練出強大的推理模型,而無需大量人類標記的數據或人類偏好,這挑戰了傳統 AI 模型訓練的範式。
- 透過 底層硬體優化,DeepSeek 降低了 AI 模型訓練和部署的成本,使得 AI 技術更加普及,不再侷限於大型企業或研究機構。
- 推動 AI 技術的開源與共享:
- DeepSeek 的 開源策略 鼓勵了更多人參與 AI 技術的開發和改進,促進了知識的共享和技術的快速發展。
- DeepSeek 開放模型權重和訓練細節的做法,有助於建立一個更加開放、透明的 AI 生態系統,吸引更多研究者共同參與,形成「韌性飛輪」效應。
- 改變 AI 產業的競爭格局:
- DeepSeek 的出現讓其他公司意識到,規模化並非 AI 發展的唯一途徑,演算法創新和底層優化同樣重要。
- 隨著 AI 模型商品化,未來的競爭將會轉向應用層面和客戶服務,而不是基礎模型的開發。
- 加速 AI 技術的普及和應用:
- DeepSeek 的低成本和高性能模型,將使得 AI 技術能夠在更多領域得到應用,例如企業內部私有 AI、個人 AI 助理等。
- AI 技術的普及將推動各行業的變革,加速人類文明的巨變 。
- 地緣政治影響 : DeepSeek 的成功顯示 中國 AI 技術正在趕上美國,對全球 AI 供應鏈和地緣政治產生影響。開放權重模型成為 AI 供應鏈的關鍵,若美國繼續打壓開源,中國可能會主導這一部分。
3. 梁文鋒對 DeepSeek 和 AI 的看法
DeepSeek 創辦人梁文鋒是一位技術出身的 CEO,對 AI 的發展有著獨到的見解 :
- 技術創新為本:梁文鋒認為,DeepSeek 的目標是參與全球創新浪潮,而不是單純追求商業利益。他強調技術創新是 DeepSeek 的核心競爭力,並認為中國 AI 不應永遠處於跟隨位置,必須做出原創性貢獻。
- 開源與生態:梁文鋒堅信建立強大的技術生態比閉源更重要,因此 DeepSeek 選擇開源其技術,吸引更多人才參與。他認為,開源能促進知識共享,加速技術發展。
- AGI 的長期目標:梁文鋒將 AGI (通用人工智慧) 作為 DeepSeek 的終極目標,認為當下的一切都只是過程,追逐技術創新是實現 AGI 的必經之路 [4, 59]。 他認為數學和程式碼是 AGI 天然的試驗場,並對多模態和自然語言本身保持開放。
- 對算力的看法:梁文鋒認為,更多的投入不一定會產生更多的創新,也並非只有高階晶片才能推動 AI 發展。DeepSeek 的成功證明,透過優化算法和軟硬體協同設計,即使在資源有限的情況下也能實現技術突破。
- 對人才的看法:梁文鋒認為,頂尖人才應該被吸引去解決世界上最難的問題,因此 DeepSeek 致力於創造一個讓技術人才可以充分發揮才能的環境 [61]。 他認為,目前中國的頂尖人才被低估了,因為社會缺乏硬派創新,讓他們沒有機會被辨識出來。
- 對技術與商業的看法:梁文鋒認為,商業上的成功應建立在技術實力的基礎之上,且要對商業抱有敬畏之心。 他強調,企業應該專注於自己擅長的領域,形成產業分工鏈,共同推動社會效率的提升。
- 對競爭的看法:梁文鋒認為,過度關注競爭會讓人眼花撩亂,更重要的是思考如何提高社會的運作效率,並在產業分工鏈上找到自己擅長的位置。
4. 針對 DeepSeek 的質疑與澄清
- 成本造假:
- 質疑:有人認為 DeepSeek 宣稱的 550 萬美元訓練成本是造假,因為沒有計入資料清理、開發人力等其他成本。
- 澄清:DeepSeek 在論文中明確指出 550 萬美元是單純的「訓練成本」,其他成本例如資料清理、開發人力等,通常不會列入計算,因為這些成本是多個模型共用的,且薪資水準在各國不同。另外,DeepSeek 使用 2048 片 H800 GPU 訓練兩個月的成本,以租賃方式計算,大約就是 550 萬美元。
- DeepSeek 是 OpenAI 的套殼:
- 質疑:有人認為 DeepSeek 回答問題時會說是 ChatGPT,所以是套殼的 [63]。
- 澄清:這僅代表 DeepSeek 的訓練資料中包含 ChatGPT 的內容,許多模型都有類似問題。且 DeepSeek 已開源,可以自行驗證。模型在訓練時並不知道自己是誰訓練的。
- DeepSeek 技術是抄來的:
- 質疑:有人認為 DeepSeek 的技術是抄襲 OpenAI 的。
- 澄清:DeepSeek 是開源的,OpenAI 是閉源的,若有抄襲,OpenAI 必須提出證據。目前沒有任何證據證明 DeepSeek 抄襲原始碼。而且,機器產生的資料不受著作權保護,DeepSeek 使用 OpenAI 產生的數據進行訓練,並不構成侵權,最多可能違反 OpenAI 的使用條款。此外,蒸餾 (distillation) 是 AI 模型訓練中常見的做法,DeepSeek 的模型性能甚至比老師模型 (o1) 更強,所以 DeepSeek 的性能並非源於抄襲。
- 混合專家架構 (MoE) 是舊技術:
- 質疑:有人認為 DeepSeek 使用的 MoE 架構是舊技術,沒有創新。
- 澄清:DeepSeek 對 MoE 架構進行了許多改進,使其效能顯著提升。
這篇文章綜合了多方資訊,希望能為您提供一個全面且深入的 DeepSeek 分析。DeepSeek 的崛起,不僅是對既有 AI 技術的挑戰,更是對未來 AI 發展方向的啟示。

發佈留言