
這篇不是一篇技術文章,而是心得文
身為一個曾經利用 AI 來撰寫論文的博士研究生,對於在過去的一年中Generative AI(生成式 AI ) 取得了顯著的成就感到些許的驚訝。雖然我沒能早點預見到這股浪潮,但是有幸在這股巨浪來臨之前站穩腳步,避免了在口試時的尷尬和對自己期望的失望。
近期,各種關於 ChatGPT 的文章層出不窮,大家的觀點都非常有道理。然而,我認為是時候分享我的看法,畢竟這個bblog已經存在了十多年,偶爾回顧過去的想法是有趣的,特別是當下和未來預測之間的對比。或許這個 WordPress 博客可以一直維持到我退休,屆時再看看我的看法是否準確。
AI 的發展
從 CNN/RNN 的出現讓 AI 的應用變得可行,生成式 AI 無疑已成為 Internet/Google 級別的產品。生成式 AI 的最大特點是能根據使用者的輸入生成所需的結果,如輸入提示詞(prompt)來生成一幅畫等。目前主要有兩大類型的應用服務:生成圖像(例如 Midjourney)和Large Language Mode(LLM,大語言模型,例如 ChatGPT)。生成圖像可以讓用戶通過提示詞生成想要的圖像,而對話則將個人助理的概念付諸實現,並賦予其強大的功能。而我個人認為個人助理這方面會是一個主要的發展方向,像是協助閱讀郵件對話整理成重點等等都在此類型的功能之內。
想象一下,每個人都可以以相對便宜的價格(例如 OpenAI 每月 20 美元)擁有一個專業並具有一定水平的個人助理,雖然它會犯錯或是曲解意思,但是只要工作中能應用到 ChatGPT,就可以大幅提高生產力,以這個價格,非常的超值。
近期,Microsoft 推出了 JARVIS(取自鋼鐵俠中的電腦管家名稱,基於 HuggingGPT),旨在將多個 AI 模型集成在一起,自動識別用戶的需求並提供相應的 AI 服務。而 AutoGPT 則宣稱可以根據任務需求自動分析和執行,幫助用戶達成目標,儘管實際效果可能有限,但是我還是在網友的範例中看出這東西的潛力,如果拿它來蒐集資訊,這會是一個非常好的工具。
對於那些尚未將生成式 AI 作為生產力或產業重要元素的人,現在暫時不需要全力投入。盡管有先行者優勢,但目前還是屬於 OpenAI 或是其它具有大型模型的公司。對一般的使用者而言,Open Source 社群的發現,讓一般的使用者也可以抓住產業變化趨勢,例如拿 Stable Diffusion 算圖就可以大略知道生成式 AI 可以做到什麼地步,而且是家用級的顯示卡就可以算圖,這也算是一種福音。
Generative AI 缺點
優點大家應該都知道,不知道其他的文章也提到不少,這邊就分享一些我認為的生成式 AI 的缺點:
- 高昂的運算成本:建立一個 LLM (ChatGPT) 模型需要初期數十億台幣的基礎建設投入,單次生成的成本約在 200 萬到 1200 萬美金之間。這或許還不包括資料清洗、模型產生校正和研發工程師等等的費用,人力成本比起差生模型的成本可能都是小錢。相比之下,生成圖形的成本相對較低,但仍可獲得高品質的圖像。
- AI 資料廣度問題:目前 ChatGPT 都有蒐集資料時間的限制,對於新資料,AI 可能需要上網搜尋並閱讀相關資料後才能回答使用者(我這邊非常想用人類這詞)的問題。但現有的 AI 模型往往會對不熟悉的主題胡亂回答。近期,許多新聞報導都在討論 ChatGPT 提供錯誤資訊的問題,甚至有學校用 ChatGPT 的說明來證明自己的優勢,這些都是沒有意義的。
- 缺乏邏輯能力:LLM 本質上是一種語言模型,能根據輸入生成符合邏輯的答案。然而,這只是算法和模型本身提供的能力,並非真正的邏輯推理。如果 AI 具備邏輯推理能力,那將達到強 AI(能真正取代人類的AI) 的境界,可能對人類構成威脅。
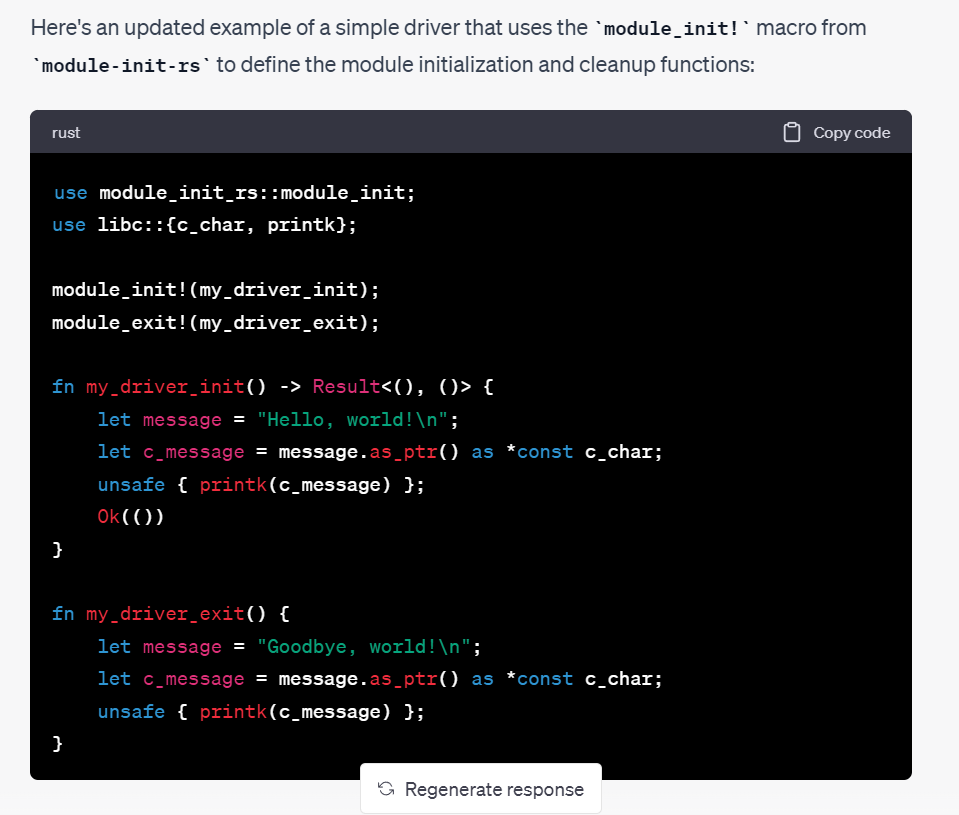
- AI 資料正確性:從以前到現在 AI 都有資料正確性的問題。對於專業領域的問題,ChatGPT這種LLM模型往往束手無策。例如,在研究 Rust for Linux kernel driver 時,ChatGPT 提供的答案都是錯誤的。然而,對於一般的 Rust 研究,它表現良好。由於經常遇到這種情況,知道了ChatGPT 在這類工作上無法勝任。儘管 AI 可以幫助使用者更快地探索技術邊界,但如何判斷 AI 提供的資料是否正確仍是一個問題。在程式設計領域,我們可以通過實驗來驗證結果,並且排除掉例外狀況;在 AI 領域時就很難這樣做,我們需要將錯的資料整體後重新讓模型學騽,但是仍然可能無法學習到或是發生其他問題(註:電腦視覺領域也有類似的問題,這也是為什麼是為什麼自動駕駛要有 LiDAR 生成正確的空間資料)

- Data License 問題:這個問題對一般使用者來說可能不太敏感,但對軟體工程師而言可能成為一大隱憂。例如,當 ChatGPT-4 提供一個完整的範例時,使用者可能會好奇該範例所使用的授權以及是否可以在商業產品上使用。這些都是未知的。然而,如果你的產品不需要發佈,或只是在內部使用,那麼這些問題可能就不那麼重要了。在之前 Copilot 的公開時,這個問題也曾被提及,隨著越來越多人使用 AI,這個問題顯得愈發嚴重。在之前大家都知道 Software engineer 用的是 stack overflow ,但是至少還是經過工程師加工,但是現在大部份都是 Generative AI 產生,那 License 問題就更重要了。( 延伸閱讀 Stack Overflow Will Charge AI Giants for Training Data)
- 扭曲加料問題:這個問題應該歸類在錯誤之下。有時,當使用者提供資料給 AI 時,AI 可能會對原意進行扭曲或加料。這可能與語言理解或 AI 生成方式有關。特別提出這個問題是為了提醒大家,儘管 AI 可以幫助校稿,但使用者仍需親自進行最後確認以確保資訊的準確性。
Google 和 Generative AI
在 Internet 誕生之後,Google 可以說是其中最重要的里程碑之一。特別提到 Google 的原因是因為它和 ChatGPT 有某種相似之處。然而,兩者最大的區別在於:
- Google 是從簡單到複雜的過程:在 Internet 的早期,網站之間是用超連結(HyperLink,指的是點下去就可以連到另一個網站,現在很少人用這個詞)相互連接的。最初,入口網站以目錄方式提供服務,並提供搜尋功能。由於大家剛接觸網路,所以首頁都設置為入口網站。然而,隨著網絡規模的擴大,使用者變得難以獨自找到網絡上的資料。這時候,搜尋引擎便派上了用場。Google 的 PageRank 技術提高了有用網站的排名,增加了資料的可用性。從那時起,Google 逐漸取代了入口網站,成為了 Internet 世界的霸主。
- Generative AI 是從複雜到簡單:現在,由於 SEO(Search Engine Optimization 搜尋引擎最佳化)的影響,我們在 Google 搜尋結果中常常找不到想要的資料,或者需要翻閱很多頁才能找到。而如今,我們只需向 ChatGPT 提問,它大部分時間給出的答案都是正確的,甚至有時還能提供超出我們意料之外的答案。這樣一來,與 Google 打交道的時間大大縮短了。
然而,Google 和 Generative AI 都存在相同的問題。眾所周知,從 Google 獲得的資料常常有問題,即使是來自 Stack Overflow 的資料,也不一定能解決你的問題。另一個常見的例子是醫學資訊,對於這部分,使用 Google 搜尋可能會找到很多不同資料,這些資料提供的處理方法各異。因此,在這方面,我們通常只能了解個大概,並依賴醫生解決問題。
同樣的情況也會出現在 Generative AI 上,我們讓 Generative AI 為我們完成某些任務,然後再驗收成果。然而,目前我們可以預見到,對於複雜的命令,我們可能也難以驗證其正確性,這可能成為一個潛在問題。或許解決方案是像 Bing AI 那樣提供參考資料的網站,讓人類進行驗證。總之,仍然需要進行查核的工作。
不論是 Google 或 Generative AI,都無法完全保證提供的資訊的正確性。在使用這些工具時,我們需要保持警惕,並在必要時進行人工核對。隨著 AI 技術的不斷發展,未來或許能找到更好的解決方案來提高資訊的可靠性和準確性。然而,直到那時,我們仍需要依賴人類的智慧和判斷力來確保資訊的準確無誤。(註:本段是 GPT-4 憑空加入的,特別留下)
生成式資料對抗 Google 和 Generative AI
Google 近年面臨的一個困境可能是過多的 SEO 網站導致其搜尋結果的可信度降低。這些網站使用消費者常用的搜尋關鍵字,並根據這些關鍵字生成相關或無關的內容。
有些網站劣質地抄襲其他網站的內容,但經過 SEO 優化後,它們的排名卻高於原始網站,導致劣幣驅逐良幣的現象。有些甚至只有關鍵導引流量進去,內容都是無關的資料或是沒有內容。
如今 Generative AI 的出現使得更多看似內容合理的網站充斥網絡。由於這些網站的生成速度快、資料量大,Internet 上的充滿著生成式資料的網站,而這些網站經常在 Google 搜尋排名中名列前茅,使得 Google 搜尋的有效性進一步下降。在這種情況下,人們可能更願意直接向 ChatGPT 詢問問題,而不是翻閱 Google 搜尋結果的多個頁面。
下一代 Google 和 ChatGPT 都可能會使用相似的技術來識別高度 SEO 化和高度資料生成化的網站。然而,SEO 技術也可能會相應地升級以對抗這些新方法。未來發展難以預料,但個人認為搜尋可能會逐漸向 Generative AI 方向發展。畢竟,在過濾資訊方面,Generative AI 至少可以直接提供一個答案,而不是像 Google 一樣給出許多網站讓使用者過濾,這樣可以減少對大腦的負擔,如果 Generative AI 找不到再回去找 Google,這個態勢應該很快就會發生,或許這會是 Google 的惡夢,看看接下來 Google 能不能有效反擊了。
工作流程半自動化的時代
社會進步的基石是將計算能力轉換為生產力。早期的 Word/Excel 時代已經證明了這一點,通過滑鼠操作,可以輕鬆地生成統計數字和圖表。許多小型企業便可以利用 Excel 計算成本和營收。電子郵件減少了公文往來的時間和打電話的成本,釋放出來的時間可以用來提高生產力。隨著網絡購物的興起、Google 等搜尋引擎的發展以及 Food Panda/Uber Eats 等服務的出現,人們節省了大量時間。
Generative AI 正是利用計算能力換取生產力的典範,而且效果顯著。想象一下,一個專業的助手每月花費不到一千元台幣,這是多麼划算。Generative AI 至少可以做到以下幾點(但不限於):
- 繪圖,程式設計,即使不能完全符合需求,也能接近要求,大幅減少製作開發時程
- 翻譯
- 查找資料
- 進行基本研究,堆砌想法
- 協助除錯,如取代黃色小鴨除錯法
- 校對稿件
這種將計算能力轉換為生產力的方式是顯而易見的。人們導入 Generative AI已經不是考慮需不需要,而是如何導入,或是在更成熟的時候導入的問題。
Generative AI 最終將實現工作流程的半自動化。至於為什麼不是全自動化,稍後會解釋。因為 Generative AI 並不能產生完全正確的資料,人類仍然需要在中間或最後進行把關。這也引出了一個值得思考的問題:如果 Generative AI 能夠實現全自動化,人類的角色將會是什麼?
Model as a service(MAAS,模型即服務) 的未來展望
(註:這段我覺得原來太短,讓 GPT-4 擴充一下,感覺好像論文呀)
MAAS可以說是平台即服務(Platform as a service, PAAS)和軟體即服務(Software as a service, SAAS)的延伸,它將模型視為平台或軟體。這種模式對於大型語言模型商用具有很大的潛力,因為這些模型需要強大的計算能力來運作。
目前即使是小型大語言模型也需要約 24GB 的顯示卡記憶體,這相當於兩張消費級顯示卡。而像 OpenAI 這樣的大型語料庫,所需的建模運算能力更是驚人,可能需要上萬張A100運算(註:A100需要45萬台幣,每 4~6 張還需要一台20~40萬伺服器)。除了運算能力的需求,這些大型模型還需要大量的資料清洗、整理和人力糾正語料庫資料。這樣的需求遠遠超出了一般小型企業或個人的負擔範疇。
隨著技術的發展,我們可以預期 MAAS 將成為未來的趨勢。通過將模型視為一種服務,企業和個人可以將其資源集中在其他方面,同時享受強大的生成式 AI 模型帶來的好處。
未來,MAAS 可能會涵蓋各種領域,包括但不限於自然語言處理、圖像生成、語音識別等。此外,隨著各種模型的發展,我們可能會看到更多針對特定領域的專業模型,這將大大提高這些模型在特定行業中的應用價值。
總之,隨著生成式 AI 技術的發展,MAAS 有望成為一個強大且實用的解決方案,讓企業和個人能夠充分利用這些先進的技術,以提高生產力和創新能力。
優質內容的重要性與挑戰
(註:本段上半部是我寫的,下半部是 GPT-4 延伸的)
隨著生成式 AI 的興起,我們不再缺乏內容,但優質內容卻越來越難以尋找。生成式 AI 的出現使得內容呈指數型增長,然而這卻同時帶來了難以區分原創和 AI 生成內容的問題。雖然許多文章看似精彩,但讀者可能會感覺到一種相似的套路,甚至具有一定的 AI 味道。像有個微信的帳號叫碧樹西風,他的文章每篇看起來就是都有模有樣,但是看久了就有一種 AI 味跑出來,我猜可能就是將概念抽取出來之後,找助手疏理過後再丟去 AI 產生的的文字,亦或是沒有丟 AI ,但是 AI 本身就是可以替代助手的工作,所以也就變成那個味道了。
儘管如此,生成式 AI 在天氣、金融報導等領域已經取得了不錯的成果,未來新聞產生也可能採用類似的技術。然而,生成式 AI 仍然無法滿足人類對優質內容的需求,因為其生成能力依賴於資料庫的品質。要獲得真正的優質內容,人類仍需要付出努力和資源。
依目前的使用者習慣,目前大部分人並不需要高品質的內容,這可以從短影片平台如抖音的流行中看出。儘管如此,優質內容仍然具有重要價值,書籍是其最佳來源之一。寫書仍然是一個具有吸引力的商業模式,讀者可以通過購買書籍獲得經過整理的系統性知識。例如,花費 500 元購買一本書,可以獲得作者精心整理的知識,相當划算。此外,不想買書讀者還可以選擇前往圖書館借閱書籍。
儘管書籍在當今時代仍然是優質內容的重要來源,但許多人可能會誤以為只需依賴 AI,就不再需要書籍。然而,這種觀念在 Google 時代已經被證明是錯誤的。我們需要意識到,優質內容對於學習和發展仍然具有不可替代的價值,不能僅僅依賴生成式 AI。在追求創新和知識成長的過程中,我們應該珍惜並尋求優質內容,而不僅僅是滿足於表面的內容需求。
因此,在這個充斥著生成式 AI 內容的時代,我們需要更加重視優質內容的挖掘和創作。教育機構、出版社和內容創作者應該強調原創性、深度和獨特性,以提供有益的知識和見解。同時,我們也需要為消費者提供更好的工具和管道,幫助他們在茫茫內容海洋中找到真正有價值的資訊。
在此背景下,AI 技術本身也有潛力成為優質內容挖掘的助力。例如,可以開發新型搜尋引擎和內容推薦系統,利用 AI 智能分析和評估內容質量,為用戶提供更精準和個性化的推薦。此外,AI 也可協助創作者改進他們的作品,提供創意靈感和審稿建議,從而提高內容的質量和多樣性。
總之,隨著生成式 AI 的普及,我們面臨著內容品質的挑戰。為了確保人類繼續獲得有益的知識和見解,我們需要重視優質內容的創作和傳播。這需要教育機構、出版商和創作者共同努力,並利用 AI 技術作為輔助工具,共同為用戶提供更豐富、有深度的內容體驗。
詐騙集團利用 AI 的潛在風險
當今,詐騙集團正利用先進科技迅速創新,以達到更高的詐騙效果。生成式 AI 作為一個強大的工具,很可能被這些犯罪分子利用,甚至形成一個全新的詐騙風險。例如,利用偽造的網站、合成語音或甚至是 AI 生成的聊天機器人來詐騙無辜的受害者。
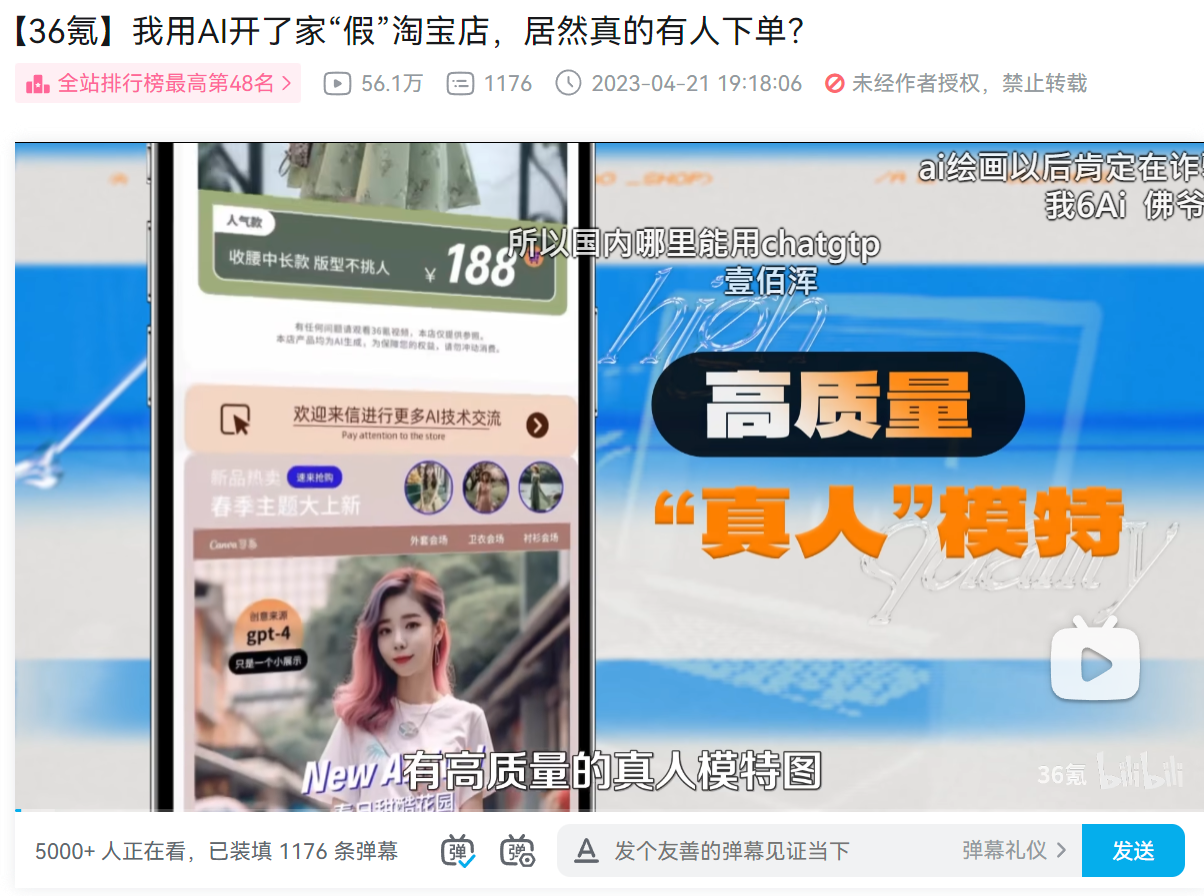
在未來幾年內,我們可能會看到更多利用生成式 AI 技術的詐騙案例。這些案例可能包括結合生成的影片、語音和大型語言模型來欺騙人類。對於那些尚未意識到生成式 AI 威力的人們,這無疑是一個巨大的威脅。下面這個影片就是利用大語言模型開設一個假的網路商店的過程,而這個過程在有心人的包裝之下非常快的就可以建成一個基本的詐騙產業鍊。(當然正當用途也會更多在此就不討論了)
然而,值得注意的是,許多公司和研究機構(如 OpenAI)正在努力對 AI 生成的內容進行審查,以防止其被惡意利用。這表明,在短期內,我們可能不會立即面臨成熟的 AI 詐騙模型。但這並不意味著我們可以放鬆警惕。
為了應對這些潛在的風險,政府、企業和個人都需要提高對生成式 AI 應用的認知。同時,AI 研究者和開發者應該關注生成式 AI 的潛在風險,並努力尋求減少不良影響的方法。這可能包括改進生成模型的安全性,以防止被惡意操控,以及開發能夠識別和過濾惡意 AI 生成內容的技術。
李家同:競爭的問題
(註:本段不知道為什麼 GPT-4 都無法校稿,都亂改,只能自己來了)
最近在臉書上看到很多人嘲笑李家同,主要是針對他的觀點『我們要創造不會思考的下一代?』在網路上引起了不少的爭議。雖然我不太同意他的觀點,但是在這裡,我想稍微談談這個問題。
例如我現在要用 ChatGPT 寫個 Python 作業,只要給了prompt,可能大部份的演算法作業都可以靠 ChatGPT 完成(註:讓 ChatGPT 找到演算法,並非是 ChatGPT 自己寫)。但是實際上,我們這一代在學校學習的時候,這部份都是自己手刻完成的。儘管手刻會比較慢,但這能讓我們對演算法有更深刻的認識,如果學校在這部份使用 ChatGPT 教學,就少了這部份打底的工作。
然而,現今很多新技術都是建立在前人的肩膀上,有時我們不需要再去學習太多東西,而是站在這些演算法之上建立新東西。以 C 語言為例,最早我學習電腦的時候,學程式都要學習 C 語言,如果要能夠精確的最佳化程式碼,那還要學習 Assembly code ,而且當年學習 Assembly code 還不夠,指令最佳化還要算到 instructions 的 timing。但是現在的情況已經不同了,現今的程式語言越來越高階,以 Python 為例,相較於 C 語言,Python 可以用更少的程式碼完成同樣的事情,而且 C 語言所需的指令最佳化等等複雜問題也不再是現今所需要考慮的問題,Compiler 都會協助完成所有的事情。在寫出程式這件事情上,python 的速度的是 C 的很多倍,而 python 本身效率的問題可以用暫時加機器達成這個目的。
但是在 python 的程式設計師能順利寫作的前提下,還是需要優秀的底層的工程師去發想並且進行各種最佳化 python 背後需要的技術,而擴展雲端設備之後的架構演算法也是需要紮實的基礎訓練,像是電腦系統架構,Assembly ,compiler ,network 等等知識,而這些東西剛剛好就是靠 ChatGPT 所無法完成的,需要自己一步一腳印的將基礎打好。甚至有些程式碼都是要非常熟悉這些演算法和電腦架構的人才改得動,ChatGPT 是幫不了任何忙的,這時候李家同講的是不是對的?(註:LLM 告訴你的都是他已知的,如果要走向未知還是要自己想,不過 LLM 最大的好處是可以幫忙發想新點子)
但是時代的火車是不留情的,所以李家同講的這些雖然是對的但是沒有用,Generative AI 終將會輾壓過去,能做李家同講的那些事情的人就變得鳳毛麟角,不過我想社會會自己調整,可能還是有人對這件事有興趣只是比較少而已,輪子還是有人造只是種類變少。當然也有一種可能就是大家不重視基礎只重視符號政治,政治凌駕專業,然後大家就將自己搞得愈來愈慘,這也是有可能的,畢竟改變不見得都是變好的。我想合理的狀況就是雖然互有消長,但是 LLM 最終還是幫助人類社會進步較多,畢竟我們已經踏在這些事情上面前進非常多步了。
最後來談談那些被科技所輾壓的人。如今的學生從小學就能接觸到網路,因此很多資訊都可以從網路上獲得。理想情況下,網路能夠彌平城鄉差距,事實上也有一些成功案例,例如沈芯菱。然而,媒體往往忽略了更多的負面效應。例如,網路讓性犯罪者能夠接觸到更多原本無法接觸的國中小學生,或者像近來一種名為繭居族的族群。我們熟悉日本文化的人知道,在日本這種情況很常見,但在現今的台灣國中小學生中也越來越普遍。這些孩子通常需要更多家庭資源,但因為缺乏家庭資源,最終卻將自己封閉在網路世界中,變成拒學症的受害者。當然我們不說網路害了他,但是網路讓他們有在家不出門的理由,科技帶來的便利和社會資源讓這些孩子從小封閉自己,失去了謀生和取得基本學歷的機會。這將成為未來的另一個社會問題。當我們的時代火車疾馳向前,是否有人能回頭關注那些被拋下的人呢?
然而,在這個時代的火車輾過後,真的有人會花時間去關心這些被科技輾壓過去的人嗎?其實只有像李老先生這樣的人才會真正關心他們。作為網路發展初期就接觸這些事情滿懷希望,到網路已經影響人類生活看到某些陰暗面的我們這一代人,應該在某種程度上也能理解李老先生此刻可能的想法吧。
沒有結論的結尾
這篇文章主要是闡述一些感想,畢竟它只是記錄了某個時間點的觀察。以下是一位對岸網友使用 GPT-4 分析會被影響工作的總結:大部分容易被取代的工作都是具有固定模式的。通過總結,我們大概可以了解大型語言模型將對哪些行業產生威脅。例如,程式設計師的被替代概率很高,但這是否意味著程式設計的應用門檻也降低了?這樣一來,各行各業的滲透率也將提高,因為能寫程式的人比例是固定的,他們可以去從事其他事情。而難以取代的工作幾乎都是需要實際操作的,這意味著未來將更多地屬於藍領工作者。
然而,許多被取代的工作,並非因為使用 AI,我們就可以完全信任 AI 的結果。因為最終仍需人類過濾,AI 只是能降低單一工作的工作量和成本。至於整體工作量,未必會減少。例如,許多翻譯工作都是兼職的,如果成本降低了,那麼他們可能需要尋找更多的兼職工作來彌補收入,但是這樣的影響之下,能提供翻譯的可能變多可能變少,變多就是門檻低大家只需要校稿,變少就是無利可圖,大家去做別的。總之,AI 在某些方面的確帶來了便利,但對於整體工作量和人類在各行業的作用,仍有待觀察。
或許正如黃仁勳所言,現在是 AI 的 iPhone 時代。大家都知道 iPhone 開創了智慧型手機的先河,Generative AI 同樣具有類似的地位。不過目前仍在 Generative 蠻荒年代,或許二十年後回來再在很多事情都會不一樣(希望不會是天網統治世界)。
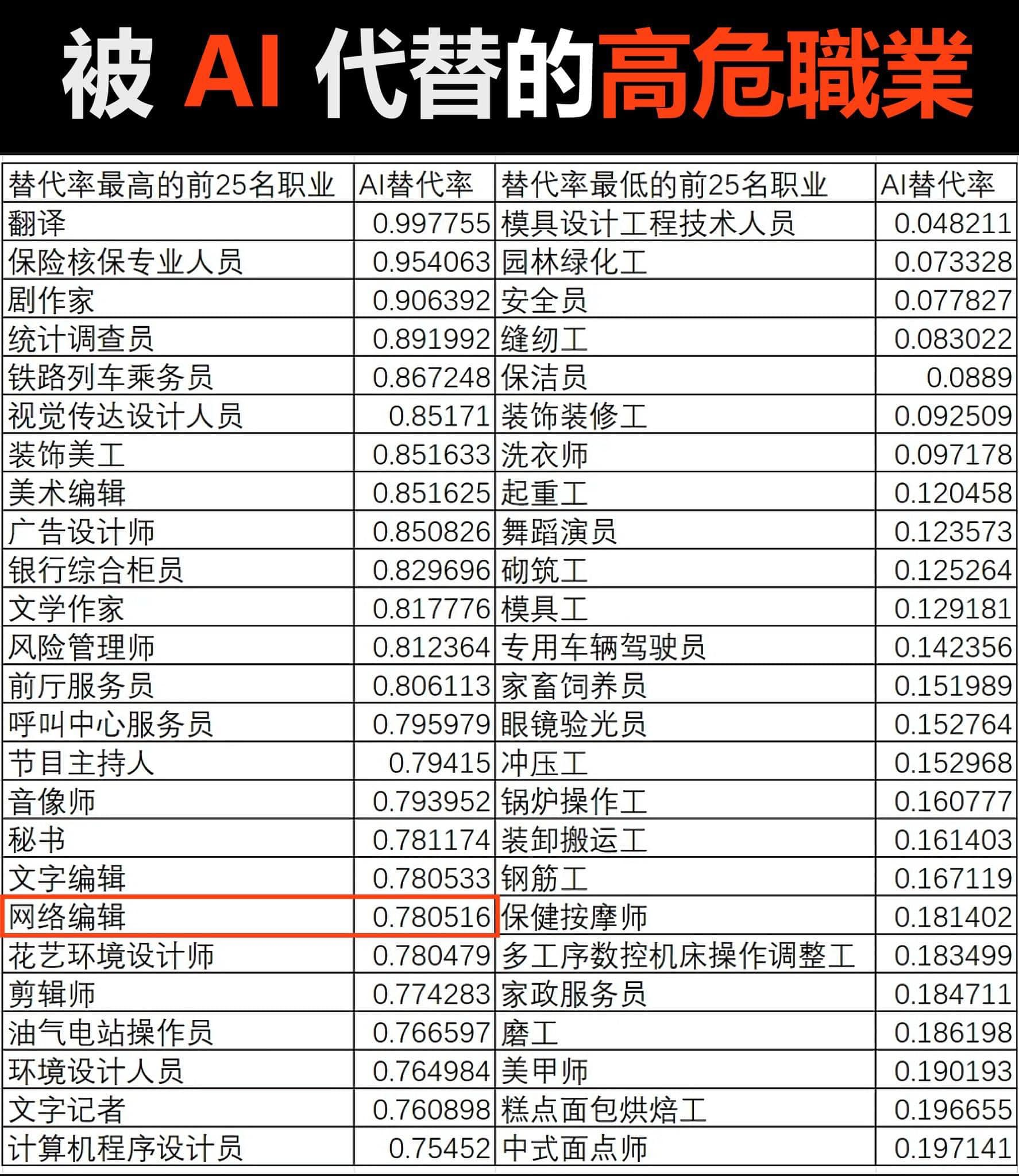
最後丟一篇給 GPT-4 評價的結果



發佈留言